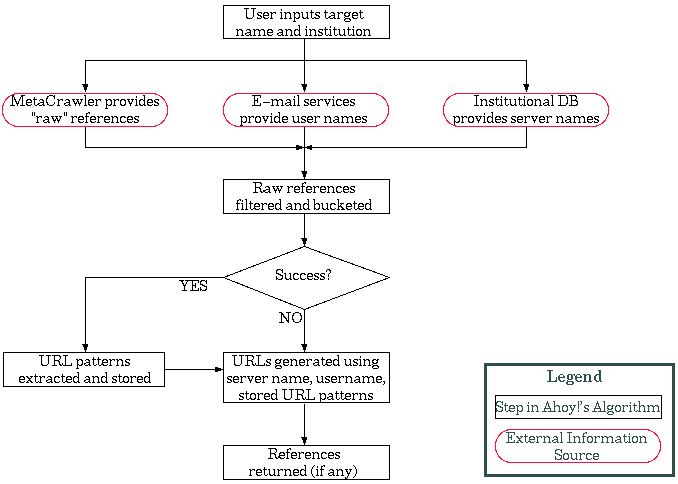
Figure 2. Architecture of Ahoy!
{jshakes|marclang|etzioni}@cs.washington.eduRobot-generated Web indices such as AltaVista are comprehensive but imprecise; manually generated directories such as Yahoo! are precise but cannot keep up with large, rapidly growing categories such as personal homepages or news stories on the American economy. Thus, if a user is searching for a particular page that is not cataloged in a directory, she is forced to query a web index and manually sift through a large number of responses. Furthermore, if the page is not yet indexed, then the user is stymied. This paper presents Dynamic Reference Sifting -- a novel architecture that attempts to provide both maximally comprehensive coverage and highly precise responses in real time, for specific page categories.
To demonstrate our approach, we describe Ahoy! The Homepage Finder (http://www.cs.washington.edu/research/ahoy), a fielded web service that embodies Dynamic Reference Sifting for the domain of personal homepages. Given a person's name and institution, Ahoy! filters the output of multiple web indices to extract one or two references that are most likely to point to the person's homepage. If it finds no likely candidates, Ahoy! uses knowledge of homepage placement conventions, which it has accumulated from previous experience, to "guess" the URL for the desired homepage. The search process takes 9 seconds on average. On 74% of queries from our primary test sample, Ahoy! finds the target homepage and ranks it as the top reference. 9% of the targets are found by guessing the URL. In comparison, AltaVista can find 58% of the targets and ranks only 23% of these as the top reference.
Information sources that are both comprehensive and precise (i.e., point exclusively to relevant web pages) are a holy grail for web information retrieval. Manually generated directories such as Yahoo! [Yahoo!, 1994] or The Web Developer's Virtual Library [CyberWeb, 1997] can be both precise and comprehensive, but only for categories that are relatively small and static (e.g., British Universities); a human editorial staff cannot keep up with large, rapidly growing categories (e.g., personal homepages, news stories on the American economy, academic papers on a topic, etc.). Thus, if a user is searching for a particular page that has yet to be cataloged in a directory, she is forced to query robot-generated web indices such as AltaVista [Digital Equipment Corporation, 1995] or Lycos [Lycos, 1995]. These automatically generated indices are more comprehensive, but their output is notoriously imprecise. As a result, the user is forced to sift manually through a large number of web index responses to find the desired reference.
Even such a laborious approach may not work. The automatically generated indices are not completely comprehensive [Selberg and Etzioni, 1995] for three reasons. First, each index has its own strategy for selecting which pages to include and which to ignore. Second, some time passes before recently minted pages are pointed to and subsequently indexed. Third, as the web continues to grow, automatic indexers begin to reach their resource limitations.
This paper introduces a new architecture for information retrieval tools designed to address the above problems. We call this architecture Dynamic Reference Sifting (DRS). It includes the following key elements:
DRS is by no means appropriate for all web searches. It works best for classes of pages with the following characteristics:
Our fundamental claim is that for these classes of pages, DRS offers significant advantages over the currently popular approaches typified by Yahoo! and AltaVista. To support this claim we developed a DRS search tool for the personal homepage category, which we call Ahoy! The Homepage Finder. Ahoy! was first tested on the web in February, 1996. The most recent version was deployed in July, 1996 and now fields over 2,000 queries per day.
The remainder of this paper is organized as follows:
Sections 2 and 3 contrast
current methods
of finding personal homepages with the
DRS approach
to this problem.
Section 4
evaluates the performance
of DRS techniques in the homepage domain.
We describe related work in Section 5,
discuss future work in Section 6, and
conclude in Section 7.
Many web users have established personal homepages that contain
information such as their address, phone numbers, schedules,
directions for visitors, and so on.
Unfortunately, homepages can be difficult to find. Most
people use one of three methods.
Method 1: Directories.
Some web services such as Yahoo! have attempted to create directories
of homepages by relying on users to register their own pages, but
such efforts have failed so far. As of November 1996,
Yahoo! contains
about 50,000 personal homepages.
It is difficult to say how many personal homepages are on the web,
but it is clear that Yahoo!'s list represents only a small fraction
of the total. For example, it contains only one percent of the
roughly 30,000
personal homepages created by
Netcom subscribers,
and it contains between one and ten percent of homepages in
other samples used to test Ahoy!.
Method 2: General-Purpose Indices.
AltaVista, Hotbot
[Hotbot, 1996],
and other general-purpose indices
make query syntax available
that is tuned to find people. This approach to finding personal
homepages avoids the problems of manually creating a list, but
the output of such searches frequently contains an inconveniently
large number of references. For example, searching AltaVista
for one of our authors using the query
"Oren NEAR Etzioni" returns about 400 references.
A similar search using
Hotbot produces over 800 matches.
A separate problem is that many search tool users do
not bother to learn the
specialized query syntax and thus request an even less precise
search.
Method 3: Manual Search.
When you know enough about a person, you can find his homepage
by first finding the web site of the person's institution, then possibly
searching down to the person's department, and finally locating a list
or index of homepages for people at that site.
Unfortunately, this method can be slow.
If, for example, you were looking for a biologist named Peter Underhill at Stanford
University, you might spend several minutes
looking through web pages of dozens of departments that might
reasonably employ a biologist.
2. Current Methods of Finding Homepages
3. Using DRS to Find Homepages
Search for a Personal Homepage |
Ahoy! represents a fourth approach to finding people's homepages. (Figure 1 shows the fields in Ahoy!'s Web interface.) We believe that Ahoy!'s DRS architecture makes it the most effective tool currently available on the web for this task. Ahoy! combines the advantages of manually-generated directories -- their relevance and reliability -- with the advantage of general-purpose search engines like AltaVista -- their enormous pool of indexed pages. In fact, due to the DRS URL Generator, Ahoy! is able to find and return homepages that are not listed in any search index. Finally, Ahoy! provides the advantage of speed: when it returns a negative result (i.e., it reports that it cannot find a given homepage), it can save its user from scanning through tens or hundreds of "falsely positive" references returned by a general-purpose search engine. In addition, Ahoy! returns a result much faster than a manual search would.
The general design of Ahoy! is shown in Figure 2. Although the behavior of each component is specific to the homepage domain, the general structure of the system could be applied to other domains as well.
Figure 2. Architecture of Ahoy!
To find the search target, a DRS system begins by forwarding the user's input to a reference source and to other, information-providing sources whose output is orthogonal to that of the reference source. In the case of Ahoy!, user input includes the name of a person and, optionally, other descriptors such as his institution and country. Ahoy!'s reference source is the MetaCrawler parallel web search service [Selberg and Etzioni, 1995]; Ahoy! gives the person's name to MetaCrawler and receives a long list of candidate web pages in return. It simultaneously submits the name to two e-mail directory services [WhoWhere?], [IAF], and determines the URL of the target person's institution using an internal database, if the user has completed the appropriate input field. These combined sources of information serve as the input to the next step, filtering.
In the filtering step, a DRS system uses two types of filters to sift out irrelevant references and rank the remaining ones: cross-filtering and heuristic-based filtering. In the homepage domain, cross-filtering helps Ahoy! reject references based on information about the target person's institution and e-mail address. Heuristic-based filtering uses heuristics that deal with people's names and the way most homepages are structured.
After filtering out obviously incorrect references, the DRS system ranks the remaining references into classes or categories called buckets. For the homepage domain, each bucket has three attributes that describe
By default, a DRS provides the user with the contents of only the most relevant buckets. In the majority of homepage searches, these relevant buckets contain one or two references. In searches where the system finds several pages that are equally likely to be relevant, however, it displays them all. If the system makes an incorrect ranking or users are curious, the contents of undisplayed, non-empty buckets are and available for viewing via hypertext link.
Pattern Extraction and Generation. A key feature of the DRS architecture is its URL Pattern Extractor, which extracts general patterns from URLs found in successful searches, and records them for future reference. The URL Generator relies on the extracted patterns to automatically synthesize URLs when a search of its references source fails. We now describe how Ahoy! implements these features.
After Ahoy! filters and buckets references, there are two possibilities: 1) Success -- After filtering, references remain in one or more buckets that we consider highly relevant to the target. Alternatively, 2) Partial Success or Failure -- Either all references have been placed in relatively low-ranked buckets, or they have all been filtered out. We examine each possibility separately below.
Success. If one or more references returned by MetaCrawler are placed in a highly-ranked bucket, Ahoy! declares success and writes the references immediately to user output. Experience with Ahoy! indicates that roughly half of queries fall under this category.
Ahoy! learns from this type of success:
a URL Pattern Extractor analyzes the references that Ahoy!
considers to be successful and extracts knowledge about their URLs.
Each success is used as a positive learning example in
the form of a triplet [name, institution, URL].
From such an example, Ahoy! learns 1) the exact identity of a server
at some institution, and 2) the pathname of a homepage
on that server. Ahoy! takes note of any substrings within the pathname
that correspond to the person's name.
The two pieces of knowledge are added to Ahoy!'s URL Pattern Database
and may be used by the URL Generator in subsequent searches.
We show an example of such use below.
Partial Success or Failure. In less successful searches, the cross-filters and heuristic-based filters may remove all references from MetaCrawler output ("Failure"), or the bucketing algorithm may not place any references in a promising bucket ("Partial Success"). Under these circumstances, control passes to the URL Generator. This module speculatively generates URLs that, if they turn out to exist, are likely to be the target homepage.
For example, if
Rob Jacob is at Tufts
but his homepage cannot be successfully found from the references returned
by MetaCrawler, then Ahoy! consults its URL Pattern Database.
During previous searches, the URL Pattern Extractor recorded
the existence of servers at Tufts called
www.cs.tufts.edu and
emerald.tufts.edu. It also noted that
www.cs.tufts.edu contained a homepage under the pathname
~[username] and that
emerald.tufts.edu contained one under
people/[username]/.
These two observations, combined with an informed guess as to
what Rob Jacob's username might be, are sufficient to generate
a set of speculative URLs for his homepage.
If the e-mail services have been successful,
the username can be extracted from an e-mail address.
Otherwise the URL Generator guesses a series of usernames for Rob Jacobs
using common username patterns
(e.g., rjacob, robjacob, rob, etc.),
combines them with server and pathname information,
and attempts to retrieve pages from:
www.cs.tufts.edu/~rjacob/
www.cs.tufts.edu/~robjacob/
www.cs.tufts.edu/~rob/
www.cs.tufts.edu/~rj/
www.cs.tufts.edu/~robj/
www.cs.tufts.edu/~jacob/
emerald.tufts.edu/people/rjacob/
emerald.tufts.edu/people/robjacob/
emerald.tufts.edu/people/rob/
emerald.tufts.edu/people/rj/
emerald.tufts.edu/people/robj/
emerald.tufts.edu/people/jacob/
Judging the performance of a web search tool is difficult. However, any evaluation of an information retrieval technique is based in part on a measure of its precision and recall. Precision measures the ratio of relevant to irrelevant information returned during a search; recall measures the ratio of relevant information returned to relevant information in existence. Typically, efforts to increase recall have come at the expense of precision, and vice-versa.
Luckily, aspects of the DRS approach provide hope that in specific domains, high precision and high recall are not mutually exclusive. The domain-specific filtering and bucketing strategy can dramatically improve precision. At the same time, successfully generating URLs that are unavailable in standard web indices can improve recall. The manner in which URLs are generated and tested makes it likely that generated references will be precise.
To demonstrate the success of Ahoy! in these areas, we present experiments that separately address precision and recall. We show that the URL-generating mechanism contributes significantly to recall. Finally, we present statistics that characterize the performance of the Ahoy! service as it is used by the web community.
Notes about the experiments
To evaluate Ahoy!'s relative performance, we ask it and four other search services -- MetaCrawler, AltaVista, Hotbot, and Yahoo! -- to find a set of known homepages. MetaCrawler is an appropriate service for comparison because Ahoy! uses MetaCrawler as its reference source. Yahoo! represents the approach of hand-compiling a directory of personal homepages. We include AltaVista and Hotbot because their indices cover a large fraction of the web, and each have query methods tailored to locating people.
Ideally, the sample of test queries would be taken from actual user queries to the fielded Ahoy! system. Unfortunately, sampling user queries is impractical. In many cases, it is difficult to determine objectively whether an obscure person mentioned by a query has a homepage or not. Users are also fond of searching for the homepages of celebrities: although the concept "celebrity" is difficult to define precisely, informal log analysis reveals that five to ten percent of searches are for celebrities. Such searches pose an unsolved testing challenge: which page(s) of the dozens devoted to an Oprah Winfrey should be considered her correct homepage(s)? Because we cannot determine "correct" answers to actual queries, we cannot judge Ahoy!'s performance on a representative sample of queries. (In Table 2, however, we present statistics that partially characterize Ahoy!'s performance on actual user queries.)
Instead of using usage logs as a source of test queries,
we use two web sites that list people
along with the URLs of their homepages. One site,
David Aha's list of Machine Learning and Case-Based
Reasoning Home Pages, contains 582 valid URLs.
We call these homepages the "Researchers sample."
Another site,
the netAddress Book of Transportation Professionals,
contains 53 URLs for individuals' homepages. We call these
homepages the "Transportation sample."
We have chosen two independently-generated samples from disparate fields in order to
evaluate Ahoy!'s scope and breadth.
As we test each competing service on the sample set, we
use query syntax that maximizes the performance of
the service in finding
personal homepages. For example, if the target homepage
belongs to John Cleary, we use AltaVista's "advanced syntax"
to search for "John NEAR Cleary" and rank the results
using the string "John Cleary."
Queries to HotBot invoke its person-specific search option.
In addition, in the tests for recall, each service returns
a large number of references -- 200 each for AltaVista and HotBot,
20 for Yahoo!, and approximately 50 for MetaCrawler.
Ahoy! typically returns one or two references.
Experiment I: Precision
The results in Figure 3 show that Ahoy!'s precision
in the homepage domain is markedly stronger than that of general-purpose
search services.
The data demonstrate precision by showing the percent of test queries
for which the target URL is at the top of the
search results.
Another way of capturing precision is to calculate the average rank
of the target URL
within the output of successful searches
(Table 1).
A low rank is good, because that means the target
reference will be displayed prominently near the top of the output.
Conversely, a high rank suggests that
irrelevant pages have been erroneously ranked higher than the target.
A very high rank also lessens the likelihood
that the user will bother to scroll down and find the target.
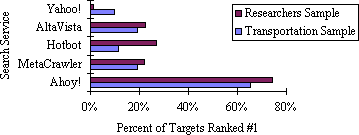 Figure 3.
Percent of homepage targets
returned as the top-ranked reference by each search service.
At this level of precision, Ahoy!'s performance is better than
that of its nearest competitor by a factor of three.
Figure 3.
Percent of homepage targets
returned as the top-ranked reference by each search service.
At this level of precision, Ahoy!'s performance is better than
that of its nearest competitor by a factor of three.
| Table 1. Precision of search for target homepages. The "Average Rank of Targets" column shows how many references a user will typically have to read through before finding the desired homepage, if the homepage is found. Ahoy! and Yahoo! place the average target page at the top of their output, while the other services tend to place the target page under several non-target references. The rank statistics are based on the Researchers sample. Statistics for the Transportation sample are comparable. |
Under the average rank metric, Ahoy!'s precision is significantly
higher than that of
every search service except Yahoo!, a manually compiled
directory of the web.
Yahoo!'s precision comes
at the expense of recall, however, as demonstrated by
Figure 4.
Experiment II: Recall
Figure 4 shows the number of targets found by various services,
regardless of the targets' location in the output. On the Researchers
sample, Ahoy! finds 9% more targets than its strongest
competitor, MetaCrawler (This increase in recall is due to Ahoy!'s URL
Generator). Furthermore, Ahoy!'s recall is significantly higher than
that of AltaVista, Yahoo!, and Hotbot on both samples.
Contribution of the URL Generator.
Although the bulk of references returned by Ahoy! are extracted from
its reference source, MetaCrawler, Ahoy! has
higher recall than MetaCrawler due to its URL generator.
Data from the fielded Ahoy! system help to explain why the URL
Generator is so effective. As of November, 1996, Ahoy!'s URL Pattern
Extractor has learned 23,000 patterns from servers at 6,000
institutions. Although the number of institutions is small compared
to the number of institutions with a web presence, the institutions
represent precisely those at which users have found homepages in past
searches. In other words, information in the URL Pattern Database is
skewed in a way that resembles the skew in Ahoy! user queries. As a
result, the URL Generator has sufficient information to
generate URLs for 34% of user queries in which the user provides
a target institution.
One or more of the URLs generated returns what Ahoy! considers
to be the target homepage on 27% of attempts at generation.
The significance of this 27% figure
is remarkable when one considers that
Ahoy! attempts generation only when it believes
the target is missing from references returned by MetaCrawler.
URL Generation is applied only to "tough" queries,
and it finds pages that are unlikely to be found using
any other method.
Experiment III: Cumulative Results
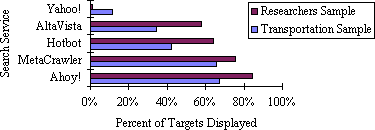 Figure 4. Percent of targets returned by each service.
Despite returning only 1 or 2 references,
Ahoy! returns a higher percentage of targets than its competitors.
When Ahoy! returns a target not located by MetaCrawler,
this reference comes from the
URL Generator.
Figure 4. Percent of targets returned by each service.
Despite returning only 1 or 2 references,
Ahoy! returns a higher percentage of targets than its competitors.
When Ahoy! returns a target not located by MetaCrawler,
this reference comes from the
URL Generator.
|
|
||||||||||||||||||||||||||||||||||||||
The design of experiments to compare the performance of different kinds of web search tools is difficult. Below, we analyze our experiments and consider experimental biases both in favor and against Ahoy!.
The discrepancy between the small number of hits returned by Ahoy! and the larger number returned by the other services biases comparisons of recall against Ahoy!: the other services are, in effect, provided many more opportunities to "get the right answer". Furthermore, note that references displayed deep in the list are of questionable value; many users are unwilling to scroll past the first ten or twenty references returned. Thus, pure recall figures understate the value added by Ahoy!.
On the other hand, the experiments contain two biases in Ahoy!'s favor. First, Ahoy! has the advantage of being domain-specific. Second, queries to Ahoy! contain the name of the target institution, information not provided to the other services. Ahoy!'s domain-specific knowledge, used in the framework of its DRS architecture, is what makes it effective, so we cannot remove the first bias without changing the fundamental nature of Ahoy!. We might, however, remove the second bias by withholding institutional information from Ahoy! or by providing such information to the other services.
By withholding institutional information, we would prevent Ahoy! from using its full set of features, including the institutional cross-filter and the URL Generator. Even so, Ahoy!'s precision under these conditions remains over fifty percent higher than that of the other services. Without benefit of the URL Generator, Ahoy!'s recall is bounded by that of MetaCrawler, its reference source. However, both MetaCrawler and the "handicapped" Ahoy! have higher recall on both test samples than the other search services.
When we provide institutional information to the general-purpose search engines, the services' precision increases slightly, and their recall decreases significantly. Why does such additional information decrease performance? We speculate:
Services like AltaVista, Hotbot, Lycos [Mauldin and Leavitt, 1994], Infoseek [Randall, 1995] and OpenText [Open Text Corporation, 1995] use keyword search. In our five-dimensional categorization, such services are comprehensive, broad in scope, highly automated, but static and imprecise. To increase precision, some services use features like phrase searching, field-based searches, and case-sensitive searching. Features relevant to finding personal homepages include nearness operators in AltaVista, specialized "person-specific" queries in Hotbot, and automatic name recognition in Infoseek's Ultraseek [Infoseek, 1996]). Nevertheless, as our experimental results demonstrate, DRS can exceed both the precision and recall of such services in carefully circumscribed categories such as personal homepages. More efficient techniques of creating and distributing such indices have been explored by the Harvest Project [Brown et al, 1994], but improved precision and recall have not yet been demonstrated. The Harvest techniques have been used to build a demonstration search service, the WWW Home Pages Harvest Broker. The broker indexes only 110,000 homepages, few of which are personal homepages.
To increase precision, directories like Yahoo! and A2Z [Lycos A2Z, 1996] provide manually-created, categorized lists of information sources. Directories improve precision at the cost of reducing automation. This tradeoff is very effective for categories that are relatively small and static (e.g., British Universities) but a human editorial staff cannot keep up with large, rapidly growing categories (e.g., personal homepages, news stories on the American economy, academic papers on a topic, etc.). This paper measures Yahoo!'s success at maintaining a complete list of personal homepages. Similar performance is exhibited by other manually-created indices that are specialized on listing homepages, including People Pages, Net Citizens, Housernet, and many other sites.
E-mail address directory services are typically static lists, automatically generated by consulting a highly restricted set of information sources. Ahoy! uses two E-mail directories for cross-filtering: Internet Address Finder and WhoWhere?. Techniques used to recognize e-mail addresses (e.g., extracting author headers on USENET postings) rely on the addresses' highly standardized form. Such techniques are not sufficient to distinguish personal homepages, unfortunately, since personal homepage URLs and contents vary widely from site to site.
Some services resemble Ahoy! in that they locate information dynamically and provide information whose scope is limited to individual people. One such service, Netfind, [Schwartz, 1991] generates the information dynamically using the Internet protocols SMTP and finger as information sources. Similar to Netfind, Ahoy! dynamically gathers information about people, but the similarity ends there. Ahoy! uses a a radically different architecture and set of information sources. Furthermore, Netfind is restricted to e-mail addresses whereas Ahoy! locates homepages.
Unlike the techniques mentioned so far, Ahoy! uses aspects of machine learning to improve its performance over time. Many machine learning systems deployed on the Web ([Knoblock and Levy, 1995]) learn about their user's tastes or activities. Examples include WebWatcher [Armstrong et al, 1995] and Syskill & Webert [Pazzani, 1995]. In contrast, Ahoy! learns about the Web itself, pooling experience gained during multiple searches by multiple users. Ahoy! is also unlike many machine learning systems in that it performs well even without learned knowledge. As a result, it can attract users immediately and use their queries to bootstrap its automatically-generated knowledge base.
Ahoy!'s learned knowledge about the web is restricted to patterns within URLs of static web pages. Increasing amounts of web information are only available from dynamic web pages generated by CGI scripts; future work is necessary to build learning agents that automatically navigate dynamic web pages. ShopBot [Doorenbos et al, 1996] is one example that automatically learns to extract information from various on-line vendors.
Ahoy! is a member of a large family of software agents investigated as part of the University of Washington's Internet Softbots project [Etzioni, 1993 and Etzioni and Weld, 1994]. Softbots (software robots) are intelligent agents that use software tools and services on a person's behalf. A person states what he wants accomplished and the softbot determines how and where to satisfy the request; the person is shielded from these details. In the case at hand, a person specifies an individual's name and affiliation --- the Ahoy! softbot is responsible for using Web resources (and filtering their output!) to locate the individual's homepage.
In the homepage domain, we believe it is possible to gain better recall and faster speeds by further developing our URL pattern extraction and URL generation algorithms. For example, we would like to have Ahoy! "learn" the canonical form of login names at various institutions. Ahoy! might learn, for example, that the homepage URL of everyone at Brown University contains two or three of the person's initials. We plan to experiment with these ideas and to test Ahoy! more broadly against a wider variety of search engines, and using larger sets of test samples.
Finally, we would like to develop DRS systems for other domains to demonstrate the general nature of the DRS architecture and more clearly define its scope. To streamline this process, we are investigating partially automating the creation of a DRS system. In particular, we are exploring techniques that would enable a DRS to automatically create its heuristic-based filter by generalizing from examples.
The most popular web search services fall into two categories: a Yahoo!-like, manually generated directory, or an AltaVista-like, automatically generated index. The former category is precise, and the latter is fairly comprehensive, but neither combines the two qualities. Dynamic Reference Sifting (DRS) represents a novel architecture for search that is highly effective for the classes of searches characterized in the introduction. By using domain-specific filtering and bucketing techniques, a DRS system can achieve all the precision of a manually-built directory. At the same time, automatic URL generation can make DRS even more comprehensive than an automatically compiled index. We have demonstrated the effectiveness of DRS using Ahoy!, a service that finds personal homepages, but we believe DRS is applicable to many other web domains.
Ahoy! would not exist without help from many people, some of whom are mentioned below. Ed Lazowska provided the original idea to build a homepage-finding agent. David Salesin inspired us to filter the output of a general-purpose search engine. Erik Selberg provided red-carpet, back-door access to MetaCrawler. UW CSE computing staff provided the infrastructure to keep Ahoy! alive. Yahoo!, IAF, OKRA, WhoWhere, Christina DeMello, Chris Redmond, and Mike Conlon generously allowed use of their data. Ellen Spertus and our fellow softboticists helped test and improve early versions of Ahoy!. Keith Golden, Richard Golding, Nicholas Kushmerick, Tessa Lau, and others provided valuable comments on earlier drafts of this paper. This research was funded in part by Office of Naval Research grant 92-J-1946, by ARPA / Rome Labs grant F30602-95-1-0024, by a gift from Rockwell International Palo Alto Research, and by National Science Foundation grant IRI-9357772.