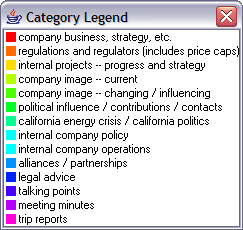
exploring enron Visualizing ANLP Results jeffrey heer [version1::white] [a course project] Professor Marti Hearst InfoSys 290-2 Applied Natural Language Processing University of California, Berkeley Fall Semester, 2004 Click any image to get a full-sized version. A power point presentation is also available. You can also download the Enronic software, which will require the Enron MySQL tables. See the Berkeley Enron Email Analysis page for more. IntroductionAlthough Applied Natural Language Processing techniques have proven useful tools for processing and understanding massive document collections, they must often be taken with a grain of salt, many times suffering from limited reliability while generating results that may prove difficult for humans to make sense of. For example, analyzing the output of unsupervised clustering routines may result in huge cluster trees over unfamiliar data. Both verifying the qualitative robustness of the results and gaining new knowledge and insight about the data would could be facilitated by additional tools. Furthermore, completely automated processing can bring its own set of dangers. Machine learning techniques may prove inaccurate or obscure patterns, especially when trusted training data is not available. One possible solution to addressing these issues is to recast ANLP and data mining techniques as accountable tools within an exploratory data environment. This requires enabling users to directly visualize and analyze the results of processing, always providing access to the underlying source data. Users can then use these tools to further their analyses, simultaneously making their own decisions about the quality of processing results and even correcting algorithms as they go. This project attempts to take the first steps toward such an exploratory data environment for e-mail corpora, using the Enron e-mail corpus as a motivating data set. The interface--currently named "enronic"--unifies information visualization techniques with various algorithms for processing the e-mail corpus, including social network inference, message categorization, and community analysis. Though still a preliminary design, enronic shows promise as a platform for more tightly coupling manual and automated data analysis. System DescriptionThis section describes the various features of the enronic corpus explorer, roughly subdivided into a social network visualization, an e-mail message viewer, and support for community structure analysis. Social Network VisualizationThere are many types of social networks that could be mined from the data. For example, with named entity recognition techniques in place, one could identify people and organizations mentioned within an e-mail body and infer social links based on textual proximity. In this case, however, I chose to use the most clear and obvious linkage - direct communication. The inferred social network is based simply on e-mail communication, that is, an e-mail from one person to another is initially treated as a directed edge from sender to recipient. In addition, I wanted to explore the annotations made by the class on the Enron e-mail data. I decided to focus on all e-mails that were categorized as having to do with Enron company business or strategy, as these are likely of greatest interest with respect to the company's illegal dealings. Furthermore, this set of e-mails is annotated with more specific business aspects, providing a fuzzy clustering ripe for visualization. I have treated these annotations as clustering results to visualize in the enronic system, though they could certainly be replaced or augmented by the output of automated clustering or classification algorithms. To facilitate visualization, I wrote SQL scripts that created database tables containing not only the social network, but for each individual message and for each link in the social network, the tally of classifications into the various categories of Enron's business. The various categories are listed in Figure 2.
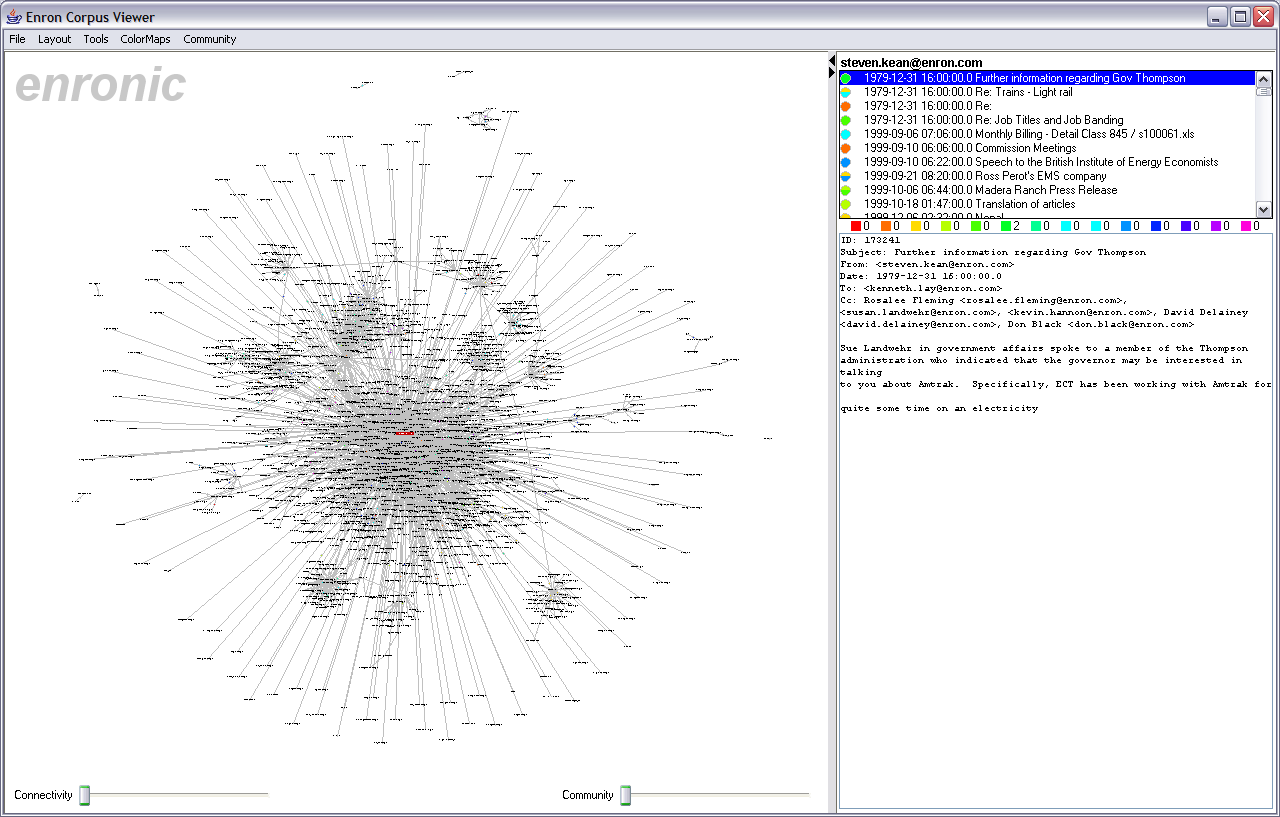
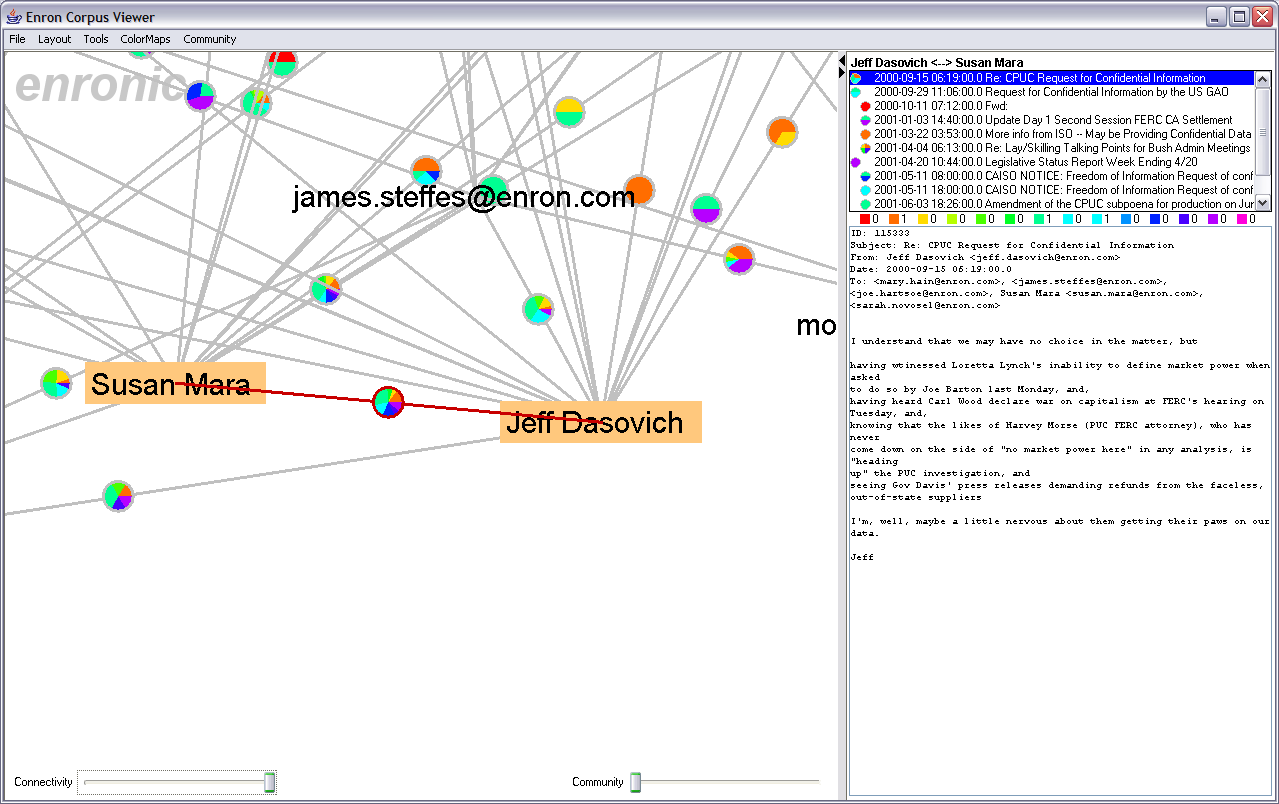
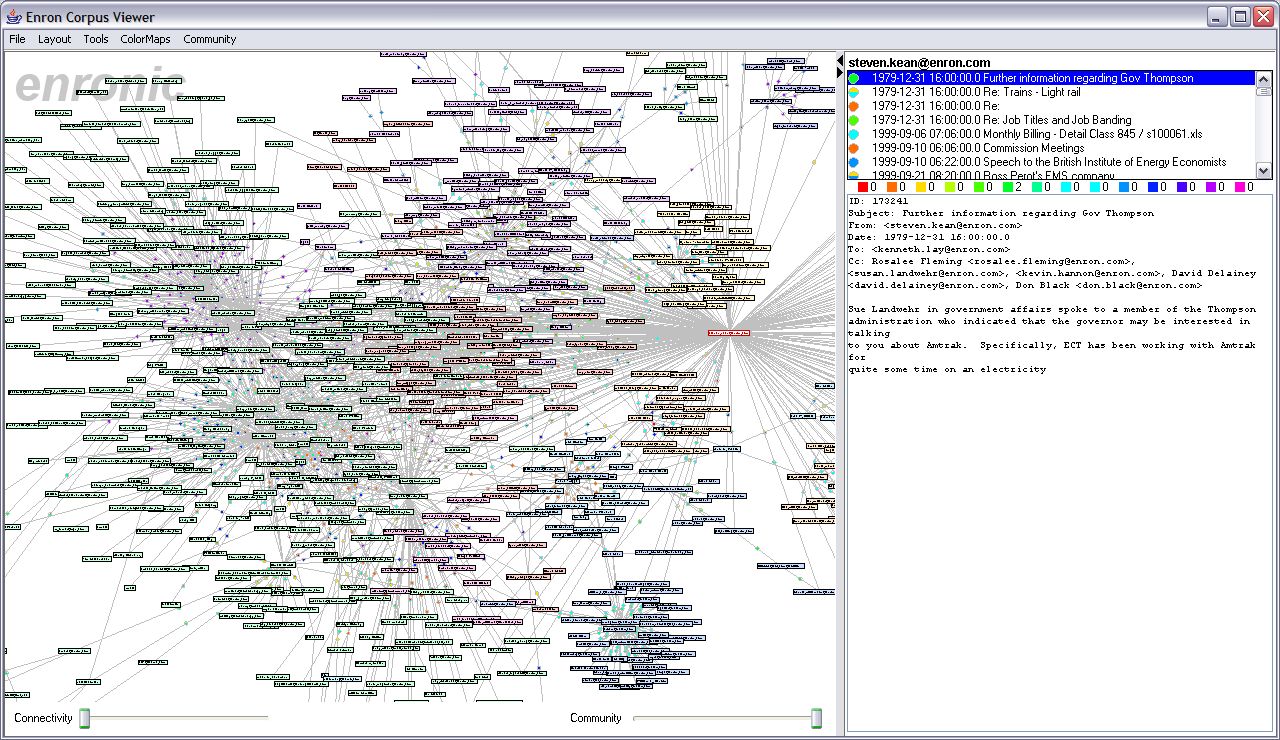
Figure 1 shows the resulting social network visualization. People are are drawn as nodes with labels containing either their name or their e-mail address, depending on what was present in the database. Edges represent the histories of ALL e-mail traffic between two people. Pie graphs are placed in the center of each edge, conveying an overall picture of how the e-mail traffic represented by that edge has been categorized. Figure 2 displays the legend mapping category colors to category labels. The graph is laid out using a spring-mass physics model. Both real-time interactive animated layouts and static layouts are available. The visualization was constructed by modifying and extending the Vizster social network visualizer [2], built atop the prefuse visualization toolkit [3].
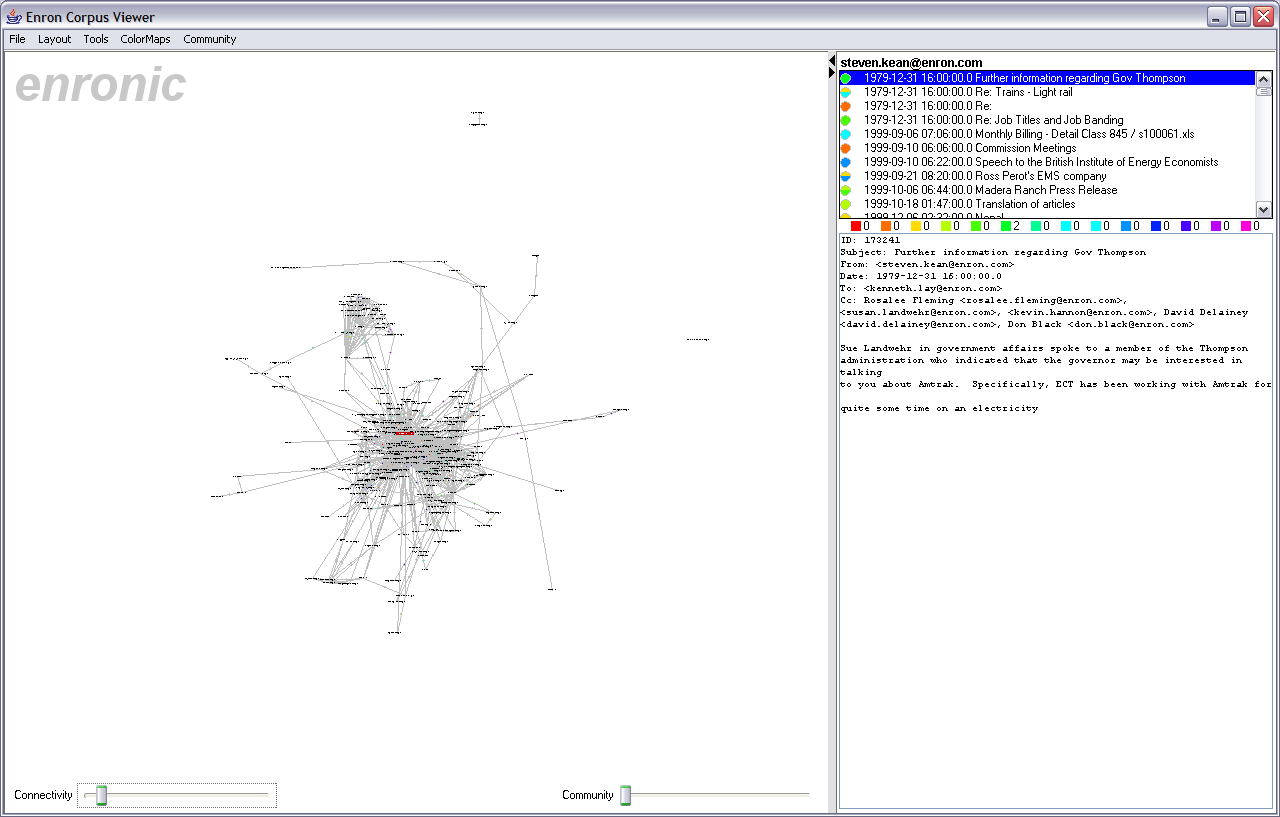
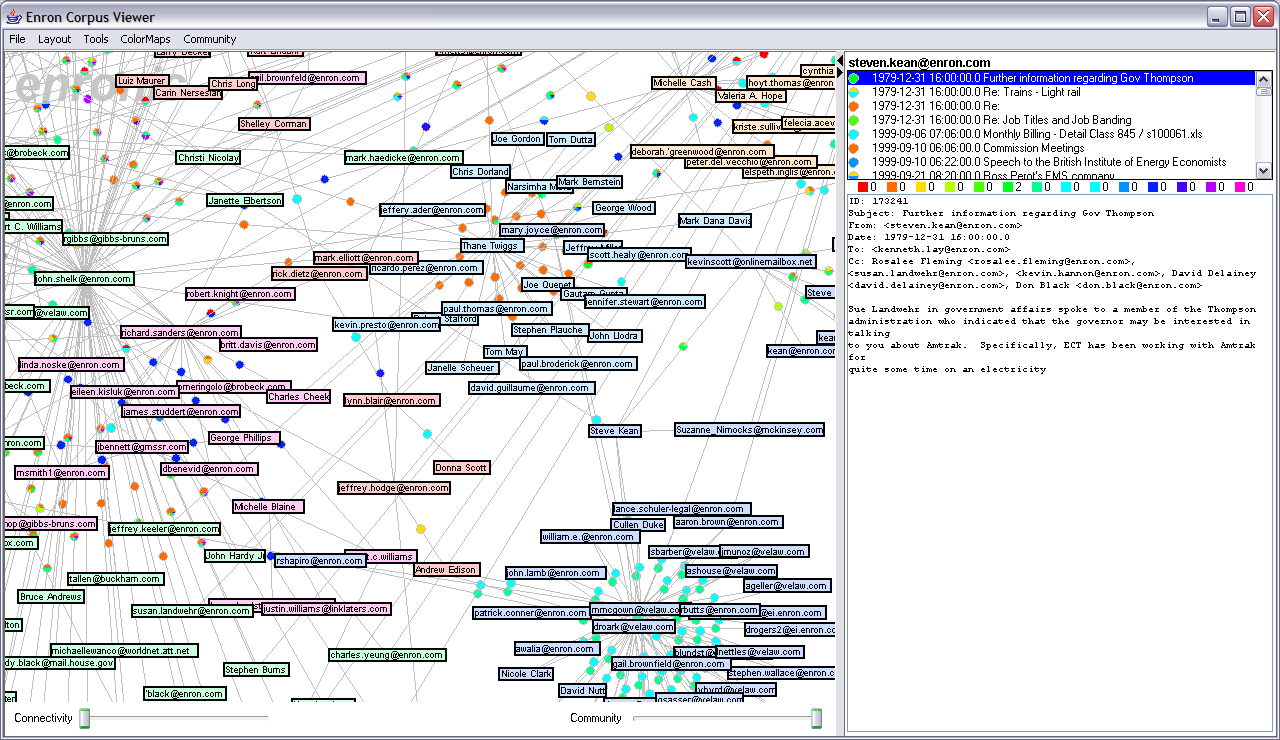
A number of interactive behaviors are available. Mousing over a node causes its adjacent edges and neighboring nodes to highlight, and mousing over an edge causes both the edge and its adjacent nodes to highlight, aiding navigation. Clicking the background and dragging causes the display to pan, while holding down the right mouse button and dragging up or down causes the display to zoom. Nodes can also be dragged around. Clicking on a node causes the entire e-mail history for a person to be displayed in the message viewer (discussed in greater detail below). Similarly, clicking on an edge causes the entire message history between the two adjacent people to be displayed in the message viewer. Additionally, a connectivity slider along the bottom of the display allows users to filter the display. Moving the slider to the right causes only nodes with increasing connectivity to remain visible, refining the network visualization to show only increasingly connected actors. There is also a community slider, described in a later section. Figures 3-6 depict the visualization in various states of exploration.
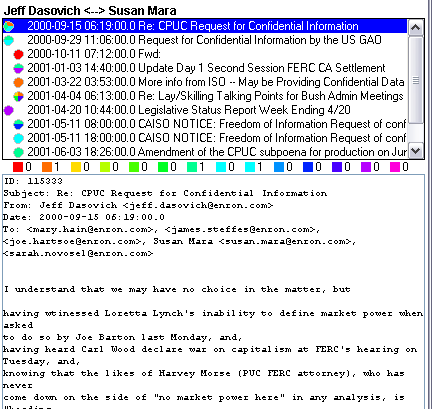
Message ViewerTo maintain access to the underlying source data, enronic includes a message viewer for displaying the e-mails in the corpus. Depending if the user clicked on a node or an edge, the viewer shows all e-mails sent or received by a given person or all e-mail traffic between two individuals, respectively. At the top of the viewer is a label showing which peoples' e-mail is currently being displayed. Below that is a list of e-mail messages, sorted by date. Each message in the list has an associated pie graph depicting the categorization of that particular message. A pie on the far left indicates that the mail was sent by the first name listed in the label (or the single person in the case of only one name in the label). A pie in the second column indicates that the first person listed received that e-mail (i.e. that it was sent by the second person in the case of an edge). Next is a series of color labels representing annotation counts for each category for the currently selected message. This is the underlying data that is used to generate the pie charts in the list above. Finally, the full text of the selected e-mail is presented.
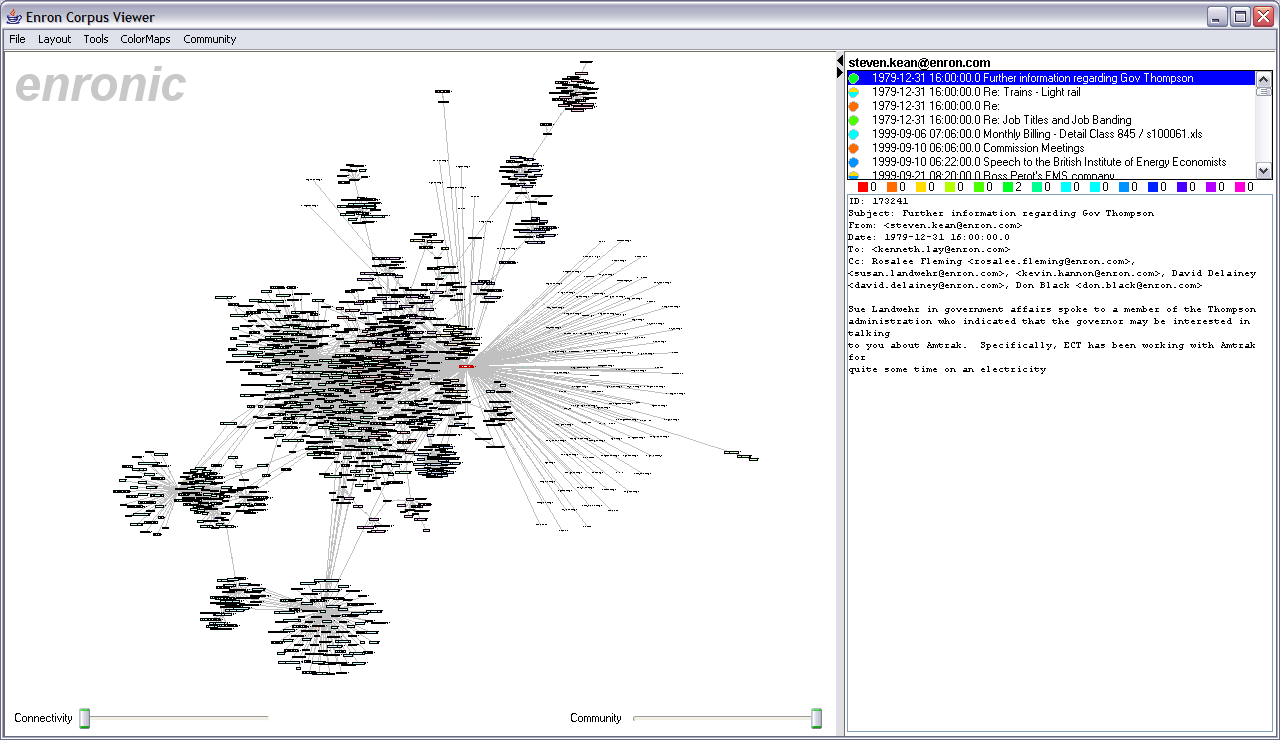
Community StructureThe application also includes an algorithm for automatically inferring the community structure of the network. To this purpose, I have implemented Newman's algorithm for fast detection of community structure [5]. The algorithm is based on a metric for community structure or network "modularity". Let eij be the fraction of links in the network between community i and community j, and let ai = Sumj eij. Then the metric Q = Sumi (eii - ai2) gives us "the fraction of edges that fall within communities, minus the expected value of the same quantity if edges fall at random without regard for the community structure" [5]. Thus a random network should give a Q value of 0, while higher values of Q indicate increasing community structure. The actual algorithm optimizes this Q value using a hierarchical agglomerative clustering approach, greedily merging communities such that the highest increase (or minimal decrease) in Q is incurred at each agglomerative step. I have made very minor alterations to Newman's algorithm so that it will work on directed graphs. This was implemented in Java using the COLT scientific computing library [4]. The output of the algorithm is the computed Q values for each iteration of the clustering, and the resulting hierarchical clustering tree. The peak value of Q indicates where to cut this dendrogram to get the optimal community structure. To activate this feature, users select "Enable Community Analysis" from the application's menu bar (Figure 8). This causes the system to create a sparse matrix representation of the current graph and submit it as input to the community structure algorithm. The visualization then takes the resulting cluster tree, reconstructs the community structure at the maximal Q value, and colors the nodes of the network to reflect the computed community assignments (Figures 9,10,11,12,13).
Users can also interactively explore the cluster tree using the provided "Community" slider at the bottom of the display. As the slider is progressively dragged from left to right the cluster assignments are updated to reflect the order of agglomerative merges made by the clustering algorithm. This allows users to interactively replay the algorithm and observe the history of community formations. This has the useful feature of revealing sub-communities that existed before a merger and provides a means to further verify the robustness of the algorithms results, which do not always match a user's expectations or desires. Figure 10 shows a close up of a set of communities, with the slider set to an intermediate position.
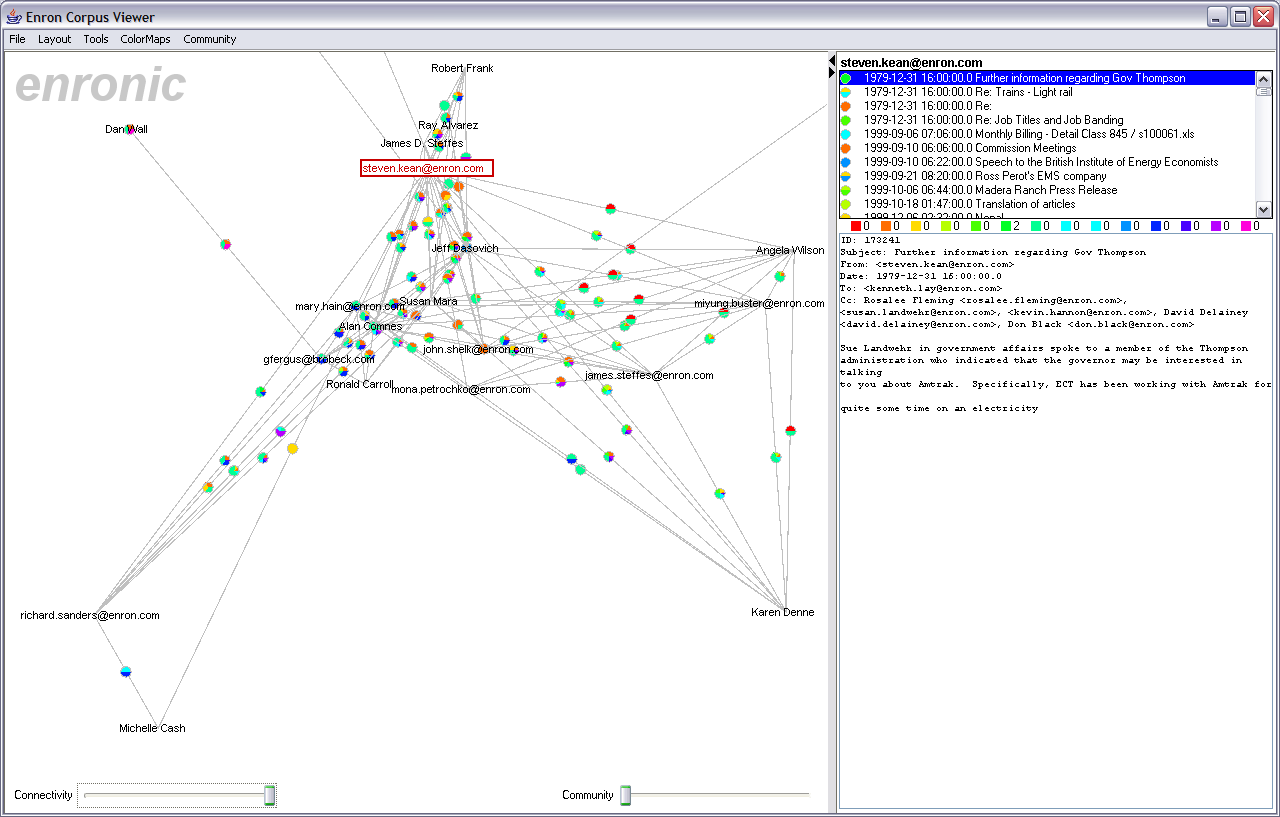
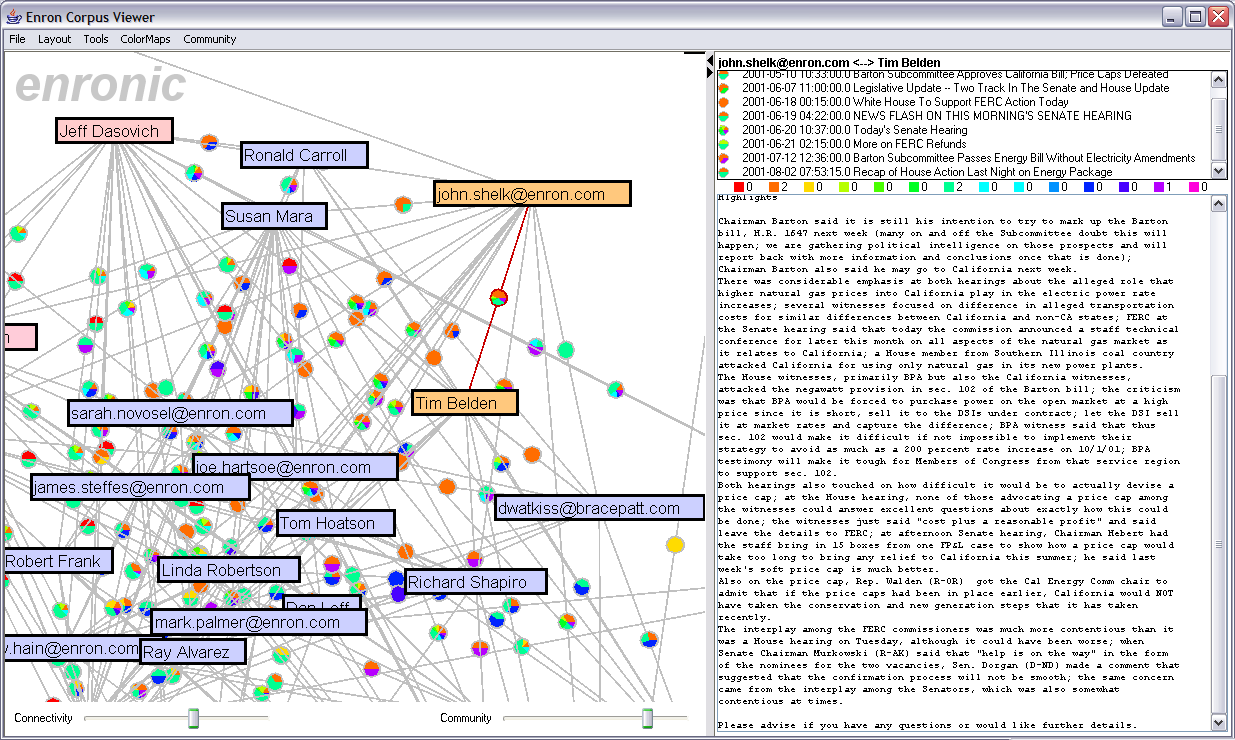
Example Analysis ScenarioSuppose we want to learn more about Enron's role in the California Energy Crisis by analyzing e-mail traffic. One aspect of this is to learn how information was being distributed within the company -- who knew what, when? Who are the "big players" that might effect Enron's corporate behavior? One way to start is to first seek out nodes that either send or receive messages from numerous employees, thus possibly representing either hubs or authorities in the network. We start by using the connectivity slider to filter the graph, revealing the more electornically-connected individuals within the organization. We can then visually search for message traffic involving the California Energy Crisis by searching the edge labels for the matching category color. One can then sample the various e-mails involved to search for clues.
Such an analysis revealed the role of John Shelk, who regularly reported on Congressional meetings, sending all such meeting reports to Tim Belden. In fact, the visualization reveals that their conversation is completely one-sided, with John sending reports to Tim, with no back-traffic occurring. This is a bit suspicious. Clicking on Tim Belden then reveals that according to the database he hasn't sent ANY e-mails, but receives various legal reports from throughout the company. This is an interesting occurrence to flag for increased investigation. It could be that Tim Belden's e-mails simply were not included in the annotation set given to the class, and this would be easy to check out (of course, ideally the interface would support this check already, a point for future improvement). Otherwise, might have his e-mails been expunged? If so why? It is clear that Tim Belden was receiving important information from throughout the organization -- what happens to this information subsequently? Is it being utilized outside of e-mail? This might highlight Tim Belden as a possibly interesting person for prosecutors investigating Enron. After performing this analysis, I did a web search on Google for "Tim Belden". I had never heard his name before doing this analysis exercise. Little did I know he was the first person charged by prosecutors, considered the "mastermind" of Enron's manipulation of California's markets, and was found guilty on charges of federal conspiracy. The full story is available at CBS News. While not a particularly rigorous analysis, this bodes well for the potential of the system. Future WorkThere is still plenty of work to be done to improve and extend the system. First, the current features can still be advanced. The color scheme can be improved, for example incorporating the color schemes presented by Ware [7], to improve visual distinctiveness of the category labels. Currently, the similar colored wedges of the pie menus can be confused for the same color in zoomed out views. Furthermore, visual analysis would benefit from much richer brushing behaviors. For example, brushing e-mail messages or category labels in the message viewer should cause corresponding items in the visualization to highlight. Filtering the visualization by category type would also be a welcome addition, and visualization of the message volume along edges could be helpful. Presenting histograms above the dynamic query sliders (e.g., the proportion of nodes over the connectivity slider, and a plot of the Q values for the community slider) might help users use those tools to better effect. It might also prove useful to provide an inverse visualization which presents messages as nodes of a graph whose linkage is determined by the people the messages have in common. Perhaps most importantly, though, is to first incorporate support for searching over the e-mail messages into the interface. A whole slew of improvements could also be made with respect to the temporal nature of the e-mail data. A range slider allowing users to filter data based on the dates of messages would undoubtedly be useful. Furthermore, it would be nice to be able to animate the evolution of the network, showing how the message traffic evolves, as well as provide keyframes from throughout this evolution to allow "small multiple" [6] type comparisons across timeslices, similar in spirit to TimeTubes [1]. Finally, there are myriad other analyses that could be incorporated, visualized, and controlled through the interface. Examples include other clustering or classification analyses, richer social network inference and analysis tools, tools for recognizing (or manually annotating) identical people with multiple e-mail addresses, and providing acronym resolution to aid sense-making of encountered e-mails. A next step would also be to allow the user to use the system to refine the output of automated processes, for example correcting an erroneous classification result. This could even be used as feedback for training any underlying machine learning algorithms. Of course, underlying this all is the challenge of architecting the system such that all these various features maintain seamless operation with each other. ConclusionThis project presents an exploratory data visualization system integrating automated applied natural language processing techniques with direct manipulation interfaces for data analysis, including the incorporation of social network inference, clustering, and community analysis with graph visualization and e-mail browsing. The system represents the first step in a larger effort to improve data analysis by recasting data mining and ANLP techniques as accountable and understandable tools under user control within a visual environment. References
1. Chi, Ed H., James Pitkow, Jock Mackinlay, Peter Pirolli, Rich Gossweiler, Stuart K. Card. Visualizing the Evolution of Web Ecologies. In Proc. of ACM CHI 98 Conference on Human Factors in Computing Systems. Los Angeles, California (1998). |