
SUPASORN SUWAJANAKORN
ABOUT
Hi! I'm Supasorn or Aek. I'm now a lecturer at VISTEC, a new research institute in Rayong, Thailand with a really nice, foresty campus. I'm looking for students, RAs/interns, postdocs, and all sorts of collaborators. Shoot me an email if you're interested. Also for PhD, please apply directly here.
News / Talks
- Two papers [1] [2] with one Oral @ CVPR 2024
- One paper [1] @ ICLR 2024!
- Three papers [1] [2] [3] @ ICCV 2023
- Two papers [1] [2] @ CVPR 2023
- One paper [1] @ ICLR 2023
- Area Chair for ICCV 2023
- Outstanding reviewer CVPR 2023
- Best Oral Presentation Award (AI Session) from PMU-B Brainpower Congress 2022.
- Our lab was awarded Google Research Gift!
- Our lab won ThaiSC HPC sponsorship!
- One Oral @ CVPR 2022 (Diffusion Autoencoders)
- Our lab won "AI for All" frontier research grant 2021! (Research and Innovation Thailand PMU)
- Our lab received an overseas Adobe Research Gift!
- Area Chair for CVPR 2022
- Two oral papers @ CVPR 2021; One best paper candidate!
- Our lab won Frontier Research Grant from Research and Innovation Thailand
- One paper accepted to ICDE 2021
- Outstanding reviewer awards: CVPR 2019, CVPR 2021
- KeyPointNet Oral @ NeurIPS 2018, Montreal
- Keynote Speaker @ O'Reilly AI Conference 2018, London
- Digital Thailand Big Bang 2018, Bangkok
- TED 2018, Vancouver
Services
- Area Chair: ICCV 2023, CVPR 2022
- Reviewer: CVPR (outstanding reviewer x 3), ICCV, ECCV, SIGGRAPH + Asia, TPAMI, IJCV, TOG
- Program Chair: MLRS 2023
Bio
Before settling down in Rayong, I was a research resident at Google Brain working on geometric understanding in deep learning and image synthesis. I finished my Ph.D. from UW working with Prof. Steve Seitz and Prof. Ira Kemelmacher in Graphics-Vision group GRAIL. My goal is to bring computer vision out of the lab into the real world and make it really work in the wild. I went to Cornell for undergrad, and had a great pleasure working with Prof. John Hopcroft on social graph algorithms, and later got inspired by Prof. Noah Snavely with his computer vision class. I love hacking, coding, tackling hard problems, and I try very hard to make my solutions as simple as possible.
Contact
My first name at gmail. If I don't reply, feel free to ping me. It's likely I lost it in the pile of 30K+ mails.
RESEARCH
CON$ULTING

|

|

|
|
| San Francisco, CA | Mountain View, CA | Bangkok, Thailand | San Francisco, CA |
WORK EXPERIENCE
|
|
AI FoundationSince 2017 I'm serving as a member of the Global AI Council, AI Foundation, a San Francisco-based company focusing on applications and platforms enabled by personal AI. |
|
Google Research InternSummer 2015 I spent a wonderful summer working with Michael Rubenstein, Ce Liu, image/video/motion analysis experts, at Google Cambridge/MIT on motion-based 3D reconstruction, and received tremendous help and input from the team with Bill Freeman, Dilip Krishnan, and Inbar Mosseri. |

|
Google Software Engineering internSummer 2013 I lingered around Seattle in 2013 and worked with Carlos Hernandez, a 3D-vision expert, and Steve Seitz, my academic advisor, at Google Seattle in Fremont on uncalibrated depth from focus and eventually published a paper two years later. In 2010 during undergrad, I interned with Harish Venkataramani as a software engineering intern at Google Mountain View on a project related to Gmail and Google+. |

|
Cornell Student Web Programmer2007 - 2008 I built a website for NY beginning farmer project under the College of Agriculture and Life Sciences and implemented a questionnaire app that helps guide farmers to the help they need. |
SOURCE CODE
My work consists of multiple large components with ten of thousands lines of code, so this will take time and I may not be able to provide support. The "research-code" is neither polished nor properly commented, but I decided to release it now for research and educational purposes. No commercial use allowed.
Synthesizing Obama: Learning Lip Sync from Audio
Here's the network training code that takes as input processed MFCC coefficients and outputs mouth fiducial points represented as PCA coefficients.
Uncalibrated Photometric Stereo
Future release.
3D Optical Flow
Future release.
PERSONAL
My other interests include: photography, 3D printing, product design, graphics design, software dev, startup, sitting in a hammock, getting lost for fun. I play badminton and squash and sports that involve gliding and wheels such as skiing, snowboarding, skating. I flew off my bike a few times and enjoyed numerous wipe-outs from surfing, but still survived. I love hacking and building things and here are some of things I built.

|
Light Field Bot - 3D PhotosphereSupasorn SuwajanakornAn automatic DSLR rig for capturing 2D/3D 360 photosphere and dense light field for VR. The rig is controlled with Wemos D1 Mini (ESP8266). It has a joystick and OLED screen for displaying menu. The structure is aluminum and 3D printed parts, designed in Fusion 360. Software and hardware are open-source. Thingiverse Stitched OmniStereo 3D Pano |

|
High-Res 360 Spherical CameraSupasorn SuwajanakornA prototype camera that automatically captures a 360 x 180 photosphere similar to Google Street View with resolution up to 100M pixel. It's a low-cost version ~$70 of gigapan made from a Raspberry Pi + custom 3D printed case. The camera rotates around the no-parallax point and is remotely controlled from a smartphone through a dedicated WiFi. Github UW MakerSpace Tour My Boston APT |
|
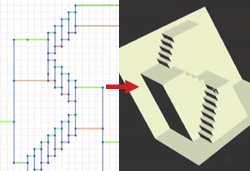
2D Pattern to 3D Origami PopupSupasorn Suwajanakorn, Jonathan Hirschberg, Roopa Roa, Michael Tomaine Winner - The Faculty Award (Boom 2011) - Cornell UniversityAn application that lets you design a 2D pattern that can be automatically turned into a 3D foldable Origami popup model. Video |

|
Low-noise Stills from VideoSupasorn Suwajanakorn, Andre Baixo Graphics Project - Graphics 2013 - UWA mobile app which combines multiple noisy shots taken hand-held into a single low-noise photo. What makes it special is that you can throw your tripod away and take pictures with your shaky hand and it will work just fine. Report |
|
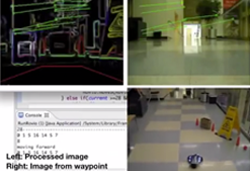
Rovio & Juliet - Autonomous Indoor Navigation using SURFJae Yong Sung, Supasorn Suwajanakorn, Jong Hwi Lee Best Project Award - Robot Learning 2011Cornell University Our goal is to make Rovio a totally autonomous robot which can follow waypoints only based on image and reach the goal position while learning and avoiding obstacles on its way. Video Report |

|
"Mech Tournament"Supasorn Suwajanakorn, Natachai Laohachai, Poom Pechavanish Best Game Award - 7th Thailand National Software Contest 2005 & Asia Pacific ICT Merit AwardsA 2D multiplayer shooting game based on DirectX 8 and DirectPlay. You get to choose your own robot and enter a battle against other players over a LAN network or against computers with challenging AI. |
|
Classroom ControllerSupasorn Suwajanakorn, Pochara Arayakarnkul Best Application Award - 6th Thailand National Software Contest 2004An application for controlling and monitoring a computer classroom. The teacher will have the ability to inspect students' screens or any running applications, limit internet or application access, issue online quizzes or polls on any machines in the classroom. |

|
Remote Fish FeederSupasorn Suwajanakorn, Naiyarit Sanpol, Thanapol Tanprayoon Winner - National Science Project Contest 2003In grade 9, I built a remote fish feeding device that is connected to a home telephone line. The device can then be activated by calling home from anywhere and press a secret passcode. Fish will thank you while you're sunbathing on a beach. |

|
Google Cardboard Positional Tracking HackSupasorn SuwajanakornI'm trying to add positional tracking to Cardboard App (Full 6DOF). Proper calibration is needed. Tracking is done on computer and position values are sent through USB to the phone (TCP via ADB). Latency is not superb, but should be better than using phone's camera and phone's processing power. Github YouTube |

|
3D Augmented-Reality Graphing CalculatorSupasorn Suwajanakorn, Yu Cheng, Cooper Findley Showcase at Boom 2011 - Cornell UnversityOur fun app that can plot a 3D graph on a piece of paper. During the contest, some number of kids had a lot of fun hand-drawing 2D patterns e.g. hearts, their names, random arts and visualizing 3D surface in real-time. |

|
jitouchSupasorn Suwajanakorn, Sukolsak Sakshuwong Runner-Up - Ars Technica Design Award Student Mac App NYTimes / macworldAn awarding-winning Mac app that expands the set of multi-touch gestures for trackpad, Magic Mouse for frequent tasks such as changing tabs in web browser, closing windows. It also recognizes handwritten alphabets as input gestures. Please check it out! Website |

|
Obox iPhoneSupasorn SuwajanakornA fast-paced puzzle game on iPhone that I made over one summer during an internship (not related). Unfortunately, it's no longer available and I did not have time to update for newer iOS. Video |

|
jiswitchSupasorn Suwajanakornjiswitch is a free Mac application that introduces a new way to switch applications. In a nutshell, it allows users to assign any window a name, and later bring that window to the top whenever the same name is typed. This tool is meant for power-users or coders who have many windows opened. Website |
Designs

|
Boom 2010 LogoSupasorn Suwajanakorn Winner - Science Showcase Logo Contest - Cornell UniversityA logo I designed for Cornell's "annual showcase of student research and creativity in digital technology and applications." I used Sunflow for global illumination rendering and Structure Synth to synthesize the model. -- Earn me an iPod touch |

|
Cornell Class of 2011 LogoSupasorn Suwajanakorn Winner - Cornell UniversityA logo selected to represent Cornell class of 2011. -- Earn me an iPod nano |

|
Cornell Minds Matter LogoSupasorn Suwajanakorn Winner - Cornell UniversityA logo selected to represent Cornell Minds Matter, an organization that promotes the overall mental and emotional health of all Cornell students. -- Earn me an iPod touch |

|
Thai Festival 2010Supasorn SuwajanakornA poster for Cornell Thai Festival 2010. It contains my hand-drawn Thai ancient art called "Lie Kranok" as seen above the text. |

|
Cornell Thai AssociationSupasorn SuwajanakornA logo for Cornell Thai Association. It's the clock tower with a new twist on the roof. |