Goal: generate a lexical analyzer automatically from a specification. The specification is a list of REs (regular expressions), with an action for each RE. Generally the action is to emit one token. Lexical analyzer generation is done in a sequence of steps:
Spec (REs+actions) -> (NFAs+actions) -> Single NFA+actions -> DFA+actions -> DFA Tables
We're going to concentrate on the first two steps.
All we need to do is convert each RE into an NFA. We learned the basic rules in lecture.
In a program (such as PA2), the REs are represented as ASTs. We convert each RE AST into an NFA by traversal.
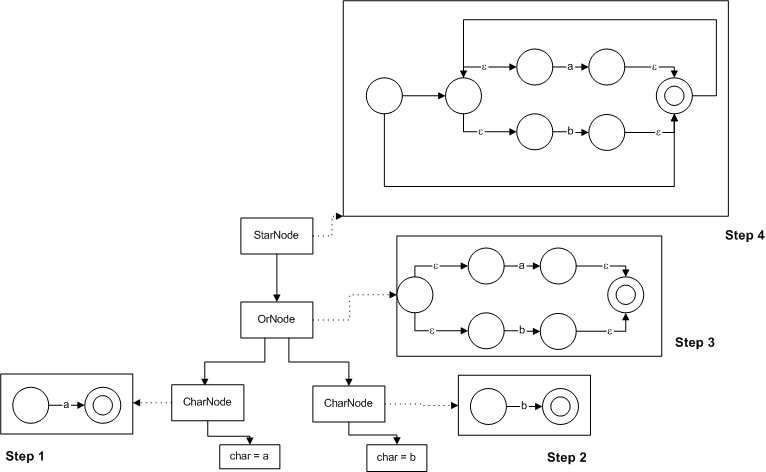
Let's convert an RE to an NFA: (a|b)*
The AST (the "true" form, by the way) for the RE is:
We traverse it in order, building up the NFAs:
Another idea: Instead of building up the NFAs, we could build up Java code that constructs the NFAs. We could include this code in the generated lexical analyzer, and we wouldn't need to ship the REs with the lexical analyzer at all.
Main points:
Where do the ASTs come from? A parser.
Would you like to write a parser as part of PA2? How about using the Java parser instead?
Isn't that crazy? Not as long as we use Java syntax. Semantics (meaning) is different, of course. So you see, syntax alone has no meaning.
We need to pick an Eclipse Java AST node class for each RE node type.
| * | PrefixExpression -- |
| + | PrefixExpression ++ |
| | | InfixExpression | |
| . | InfixExpression & (why not InfixExpression . ?) |
| 'a' | IntegerLiteral Character.intValue('a') |
Main points:
Now we want to combine all NFAs into a single NFA.
To combine the NFAs, it's just the OR construction. But what about the actions? Where do they go?
First try: put each action with the final state in the NFA it came with. When we reach the final state, do the action.
Problem: what if we have 2 REs, "for" and "foreach". We know that we want to match the longest. But when we have read 'f', 'o', 'r', we will do the "for" action right away. Bad!
Second try: when we reach the final state, remember state and position in input. Keep running NFA. When we get stuck, return to remembered state and position. Do the action, and start over.
Problem: what if we have 2 REs, "if", and "{alphanum}*"? On input 'i', 'f', space, they both match at same time?
Third try: assign priority to each RE. Take the one with the highest priority when both match. In practice, usually give the one that came first in the spec file higher priority.
Main points:
Now it works. We don't have a traditional recognizer NFA anymore. Basic NFAs don't have actions or priority. But it works as a lexical analyzer.
[Example]
// Declarations
ALPHA = ['_', 'A'-'Z', 'a'-'z']
ALPHANUM = ['0'-'9', '_', 'A'-'Z', 'a'-'z']
// Rules
{ALPHA}{ALPHANUM}* { return new Token(ID); }
'i' 'f' { return new Token(IF); }
'w' 'h' 'i' 'l' 'e' { return new Token(WHILE); }
'=' { return new Token(EQUALS); }
'-' { return new Token(PLUS); }
'+' { return new Token(MINUS); }
'"' .* '"' { return new Token(STRING); }
' '+ { return nextToken(); }