Magdalena Balazinska
|
Paul Castro
|
Disclaimer: The authors do not provide any warranty what so ever ;-)
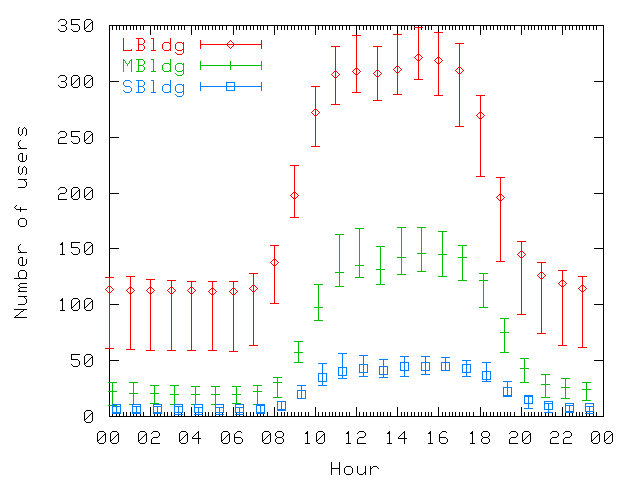
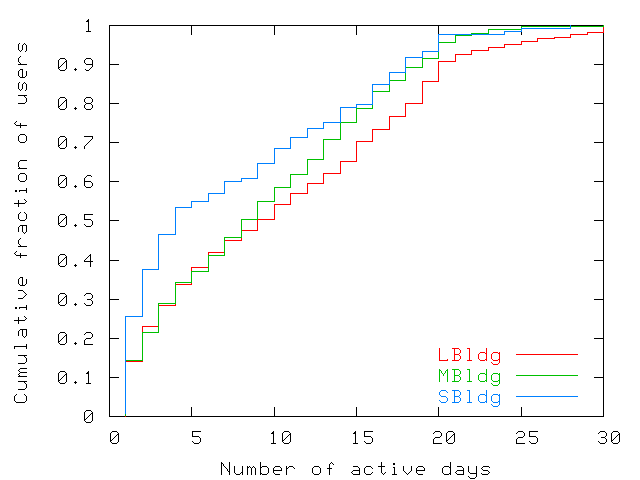
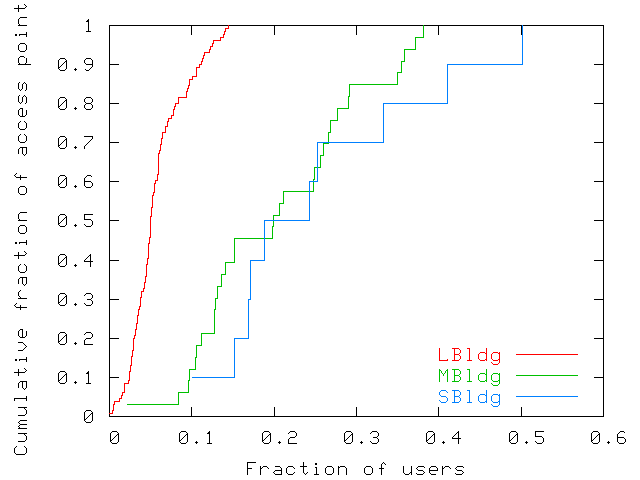
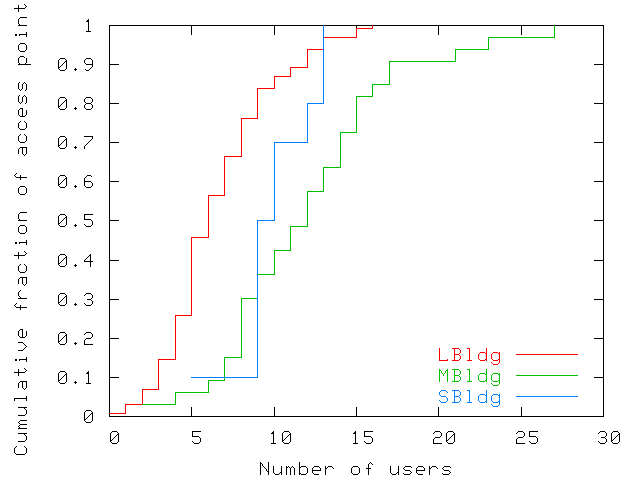
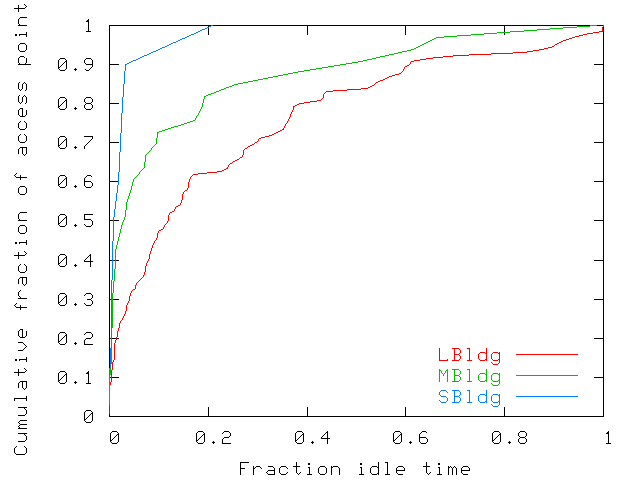
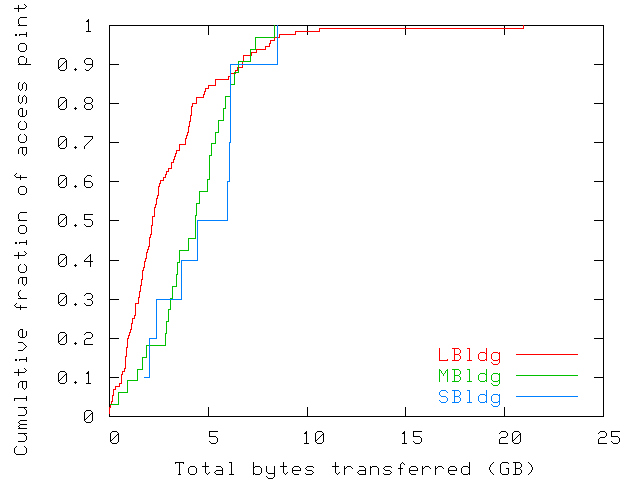
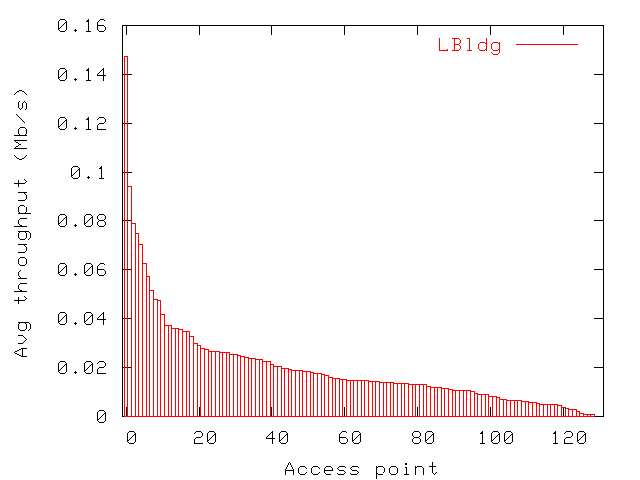
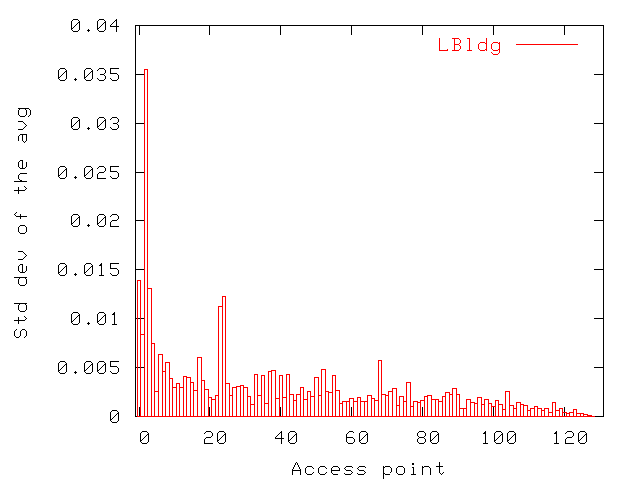
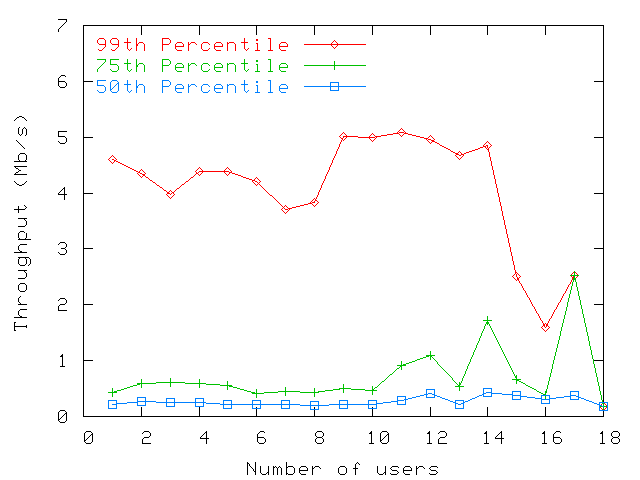
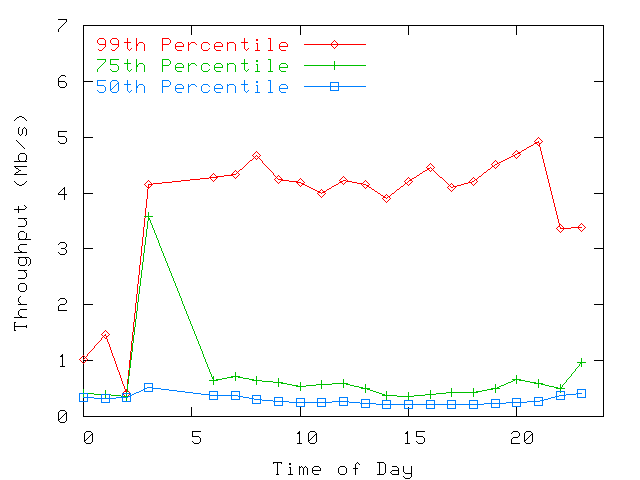
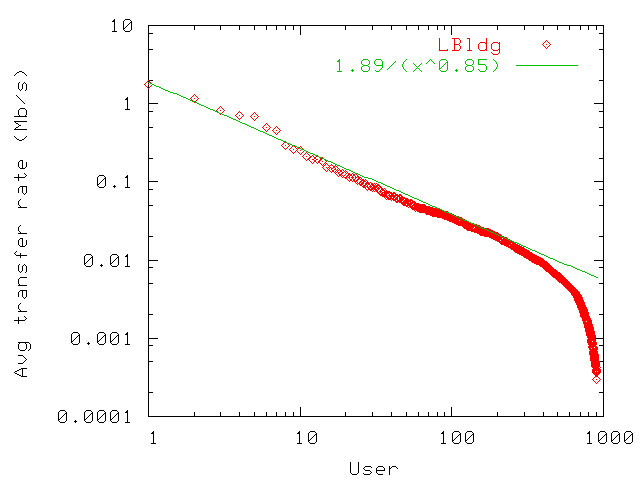
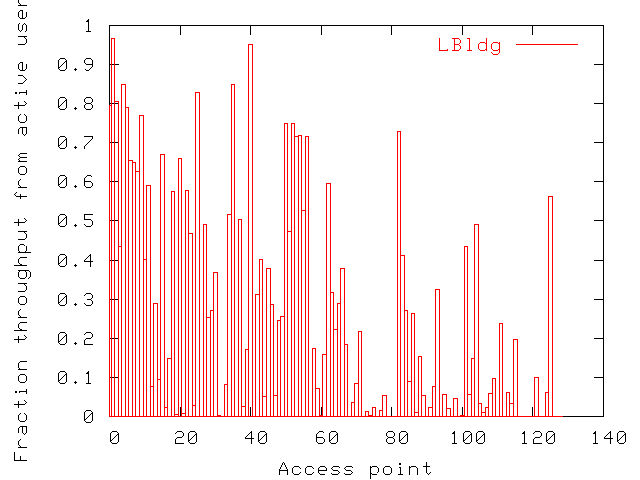
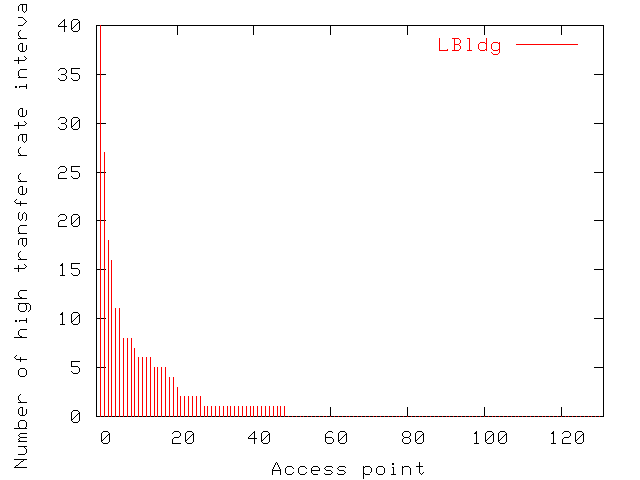
| LBldg | MBldg | SBldg | |
| one bldg | 81% | 55% | 72% |
| two bldgs | 16% | 34% | 26% |
| three bldgs | 3% | 11% | 2% |
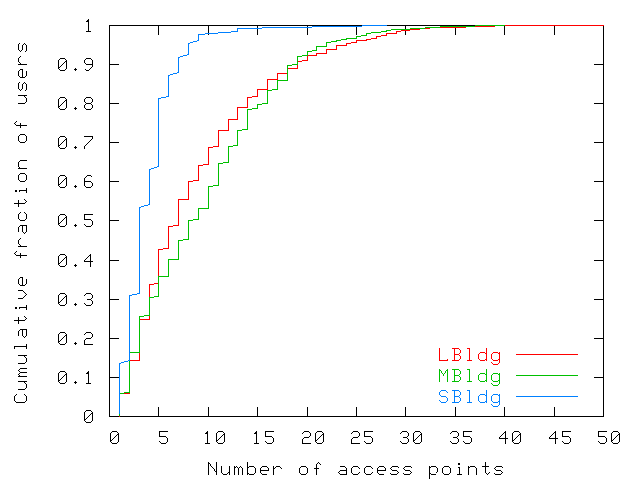
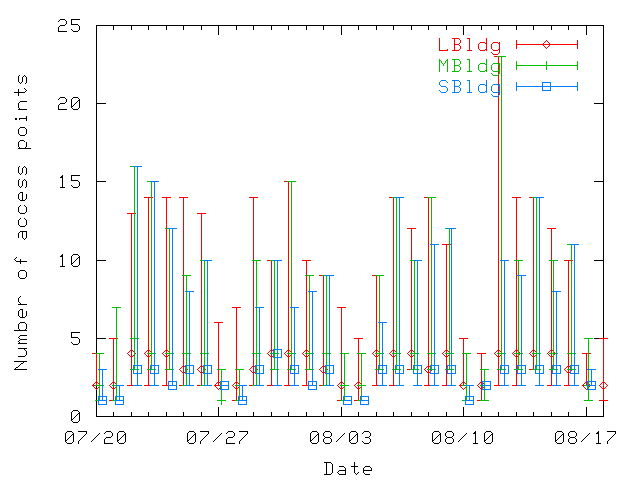
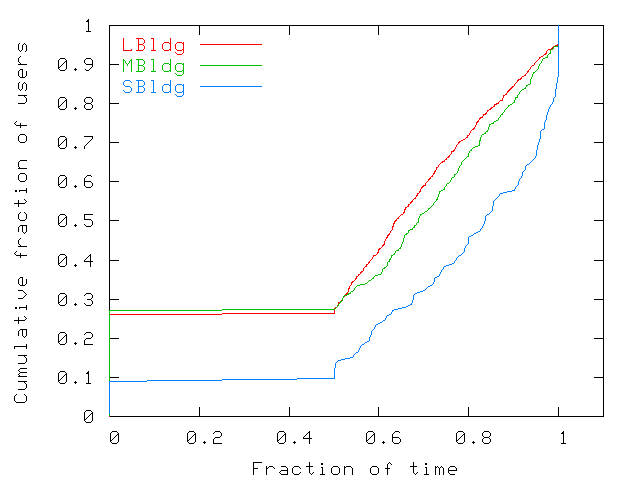
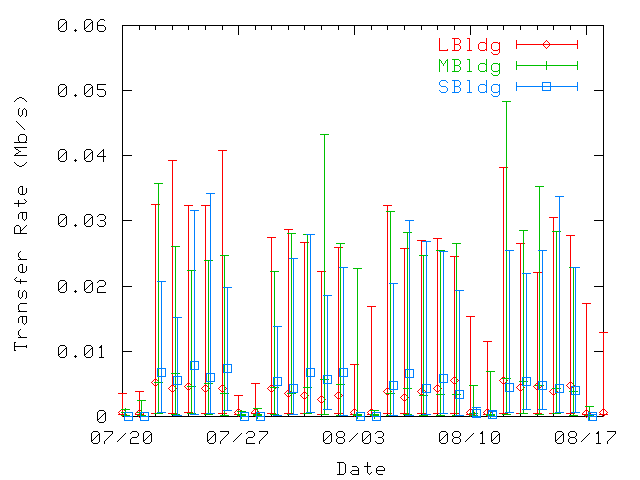
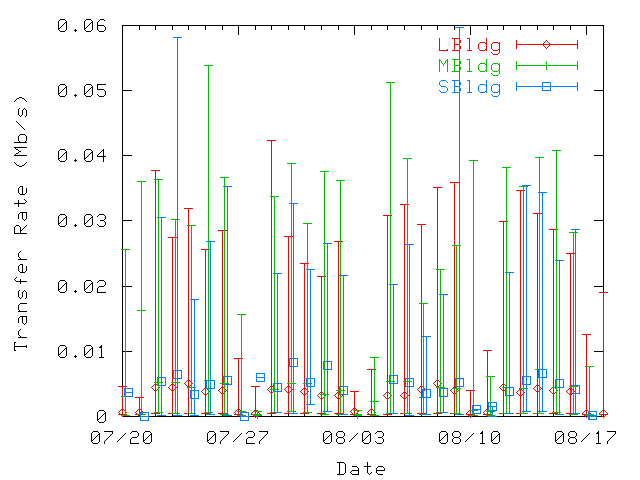
| U1 | U2 | ... | Un | |
| AP1 | Prev1,1 | Prev2,1 | ... | Prevn,1 |
| Ap2 | Prev1,2 | Prev2,2 | ... | Prevn,2 |
| ... | ... | ... | ... | |
| APk | Prev1,k | Prev2,k | ... | Prevn,k |
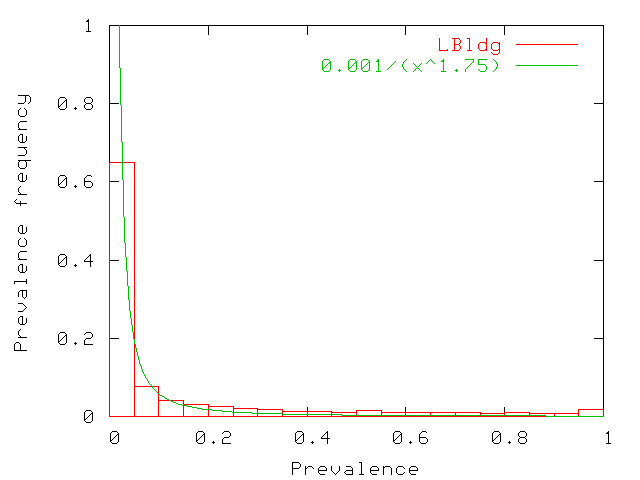
| Median Prevalence (Pmed) | |||
| Maximum Prevalence (Pmax) | Low Pmed ε [0,0.25) |
Med Pmed ε [0.25,0.50) |
High Pmed ε [0.50,1] |
| Low Pmax ε [0,0.33) |
highly mobile (4%,6%,0%) | N/A | N/A |
| Medium Pmax ε [0.33,0.66) | somewhat mobile (38%,29%,11%) | regular (10%,11%,13%) | N/A |
| High Pmax ε [0.66,1] |
occ mobile (39%,44%,44%) | N/A | stationary (9%,10%,32%) |