Abstract: This work present novel method for structure estimation of an underlying dynamical system. We tackle problems of estimating dynamic structure from bandit feedback contaminated by sub-Gaussian noise. In particular, we focus on periodically behaved discrete dynamical system in the Euclidean space, and carefully identify certain obtainable subset of full information of the periodic structure. We then derive a sample complexity bound for periodic structure estimation. Technically, asymptotic results for exponential sums are adopted to effectively average out the noise effects while preventing the information to be estimated from vanishing. For linear systems, the use of the Weyl sum further allows us to extract eigenstructures. Our theoretical claims are experimentally validated on simulations of toy examples, including Cellular Automata.
BibTex: @article{DSEfBF,
title={Dynamic Structure Estimation from Bandit Feedback},
author={Ohnishi, M. and Ishikawa, I. and Kuroki, Y. and Ikeda, M.},
journal={arXiv preprint arXiv:2206.00861},
year={2022}
}
Abstract: Most modern reinforcement learning algorithms optimize a cumulative single-step cost along a trajectory. The optimized motions are often 'unnatural', representing, for example, behaviors with sudden accelerations that waste energy and lack predictability. In this work, we present a novel paradigm of controlling nonlinear systems via the minimization of the Koopman spectrum cost: a cost over the Koopman operator of the controlled dynamics. This induces a broader class of dynamical behaviors that evolve over stable manifolds such as nonlinear oscillators, closed loops, and smooth movements. We demonstrate that some dynamics realizations that are not possible with a cumulative cost are feasible in this paradigm. Moreover, we present a provably efficient online learning algorithm for our problem that enjoys a sub-linear regret bound under some structural assumptions.
BibTex: @article{KSNR,
title={Koopman Spectrum Nonlinear Regulator and Provably Efficient Online Learning},
author={Ohnishi, M. and Ishikawa, I. and Lowrey, K. and Ikeda, M. and Kakade, S. and Kawahara, Y.},
journal={arXiv preprint arXiv:2106.15775},
year={2021}
}
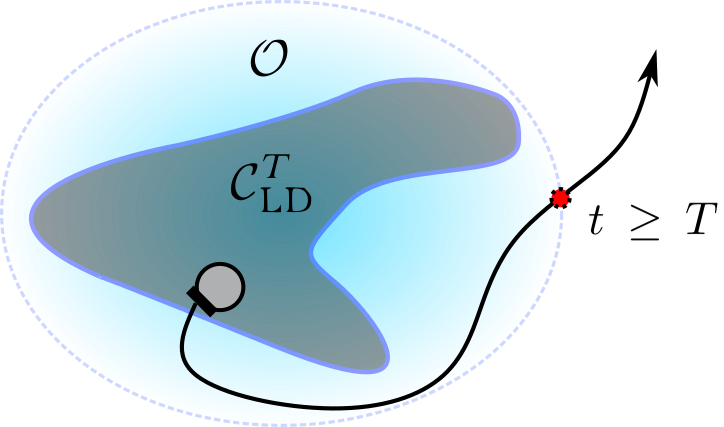
Abstract: When deploying autonomous agents in unstructured environments over sustained periods of time, adaptability and robustness
oftentimes outweigh optimality as a primary consideration. In other words, safety and survivability constraints play a key role and in this paper, we present a novel, constraint-learning framework for control tasks built on the idea of constraints-driven control. However, since control policies that keep a dynamical agent within state constraints over infinite horizons are not always available, this work instead considers constraints that can be satisfied over some finite time horizon T > 0, which we refer to as limited-duration safety. Consequently, value function learning can be used as a tool to help us find limited-duration safe policies. We show that, in some applications,
the existence of limited-duration safe policies is actually sufficient for long-duration autonomy. This idea is illustrated on a swarm of
simulated robots that are tasked with covering a given area, but that sporadically need to abandon this task to charge batteries.
We show how the battery-charging behavior naturally emerges as a result of the constraints.
Additionally, using a cart-pole simulation environment, we show how a control policy can be efficiently transferred from the source task,
balancing the pole, to the target task, moving the cart to one direction without letting the pole fall down.
BibTex: @article{ohnishi2021constraint,
title={Constraint Learning for Control Tasks with Limited Duration Barrier Functions},
author={Ohnishi, M. and Notomista, G. and Sugiyama, M. and Egerstedt, M.},
journal={Automatica},
volume={127:109504},
year={2021}
}
Abstract: This work studies the problem of sequential control in an unknown, nonlinear dynamical system, where we model the underlying system dynamics as an unknown function in a known Reproducing Kernel Hilbert Space. This framework yields a general setting that permits discrete and continuous control inputs as well as non-smooth, non-differentiable dynamics. Our main result, the Lower Confidence-based Continuous Control (LC3) algorithm, enjoys a near-optimal O(√T) regret bound against the optimal controller in episodic settings, where T is the number of episodes. The bound has no explicit dependence on dimension of the system dynamics, which could be infinite, but instead only depends on information theoretic quantities. We empirically show its application to a number of nonlinear control tasks and demonstrate the benefit of exploration for learning model dynamics.
BibTex: @inproceedings{LC3,
title={Information Theoretic Regret Bounds for Online Nonlinear Control},
author={Kakade, S. and Krishnamurthy, A. and Lowrey, K. and Ohnishi, M. and Sun, W.},
booktitle={Advances in Neural Information Processing Systems},
year={2020}
}
Abstract: This paper presents a safe learning framework that employs an adaptive model learning algorithm together with barrier certificates for systems with possibly nonstationary agent dynamics. To extract the dynamic structure of the model, we use a sparse optimization technique. We use the learned model in combination with control barrier certificates which constrain policies (feedback controllers) in order to maintain safety, which refers to avoiding particular undesirable regions of the state space. Under certain conditions, recovery of safety in the sense of Lyapunov stability after violations of safety due to the nonstationarity is guaranteed. In addition, we reformulate an action-value function approximation to make any kernel-based nonlinear function estimation method applicable to our adaptive learning framework. Lastly, solutions to the barrier-certified policy optimization are guaranteed to be globally optimal, ensuring the greedy policy improvement under mild conditions. The resulting framework is validated via simulations of a quadrotor, which has previously been used under stationarity assumptions in the safe learnings literature, and is then tested on a real robot, the brushbot, whose dynamics is unknown, highly complex and nonstationary.
BibTex: @article{ohnishi2019barrier,
title={Barrier-certified adaptive reinforcement learning with applications to brushbot navigation},
author={Ohnishi, M. and Wang, L. and Notomista, G. and Egerstedt, M.},
journal={IEEE Trans. Robotics},
volume={35},
number={5},
pages={1186--1205},
year={2019}
}
}
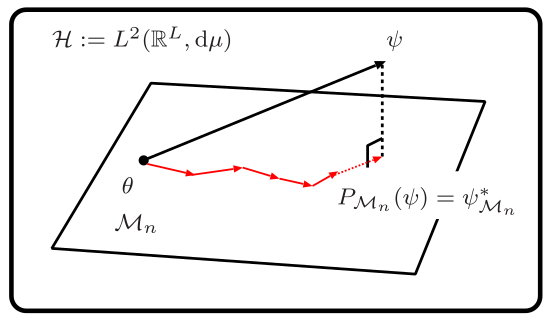
Abstract: We propose a novel online learning paradigm for nonlinear-function estimation tasks based on the iterative projections in the L2 space with probability measure reflecting the stochastic property of input signals. The proposed learning algorithm exploits the reproducing kernel of the so-called dictionary subspace, based on the fact that any finite-dimensional space of functions has a reproducing kernel characterized by the Gram matrix. The L2-space geometry provides the best decorrelation property in principle. The proposed learning paradigm is significantly different from the conventional kernel-based learning paradigm in two senses: first, the whole space is not a reproducing kernel Hilbert space; and second, the minimum mean squared error estimator gives the best approximation of the desired nonlinear function in the dictionary subspace. It preserves efficiency in computing the inner product as well as in updating the Gram matrix when the dictionary grows. Monotone approximation, asymptotic optimality, and convergence of the proposed algorithm are analyzed based on the variable-metric version of adaptive projected subgradient method. Numerical examples show the efficacy of the proposed algorithm for real data over a variety of methods including the extended Kalman filter and many batch machine-learning methods such as the multilayer perceptron.
BibTex: @article{ohnishi2018online,
title={Online Nonlinear Estimation via Iterative $ L\^{} 2$-Space Projections: Reproducing Kernel of Subspace},
author={Ohnishi, M. and Yukawa, M.},
journal={IEEE Trans. Signal Processing},
volume={66},
number={15},
pages={4050--4064},
year={2018}
}
Abstract: Motivated by the success of reinforcement learning (RL) for discrete-time tasks such as AlphaGo and Atari games, there has been a recent surge of interest in using RL for continuous-time control of physical systems (cf. many challenging tasks in OpenAI Gym and DeepMind Control Suite). Since discretization of time is susceptible to error, it is methodologically more desirable to handle the system dynamics directly in continuous time. However, very few techniques exist for continuous-time RL and they lack flexibility in value function approximation. In this paper, we propose a novel framework for model-based continuous-time value function approximation in reproducing kernel Hilbert spaces. The resulting framework is so flexible that it can accommodate any kind of kernel-based approach, such as Gaussian processes and kernel adaptive filters, and it allows us to handle uncertainties and nonstationarity without prior knowledge about the environment or what basis functions to employ. We demonstrate the validity of the presented framework through experiments.
BibTex: @inproceedings{ohnishi2018continuous,
title={Continuous-time value function approximation in reproducing kernel {H}ilbert spaces},
author={Ohnishi, M. and Yukawa, M. and Johansson, M. and Sugiyama, M.},
booktitle={Advances in Neural Information Processing Systems},
pages={2813--2824},
year={2018}
}
Abstract: This paper presents a safe learning framework that employs an adaptive model learning algorithm together with barrier certificates for systems with possibly nonstationary agent dynamics. To extract the dynamic structure of the model, we use a sparse optimization technique. We use the learned model in combination with control barrier certificates which constrain policies (feedback controllers) in order to maintain safety, which refers to avoiding particular undesirable regions of the state space. Under certain conditions, recovery of safety in the sense of Lyapunov stability after violations of safety due to the nonstationarity is guaranteed. In addition, we reformulate an action-value function approximation to make any kernel-based nonlinear function estimation method applicable to our adaptive learning framework. Lastly, solutions to the barrier-certified policy optimization are guaranteed to be globally optimal, ensuring the greedy policy improvement under mild conditions. The resulting framework is validated via simulations of a quadrotor, which has previously been used under stationarity assumptions in the safe learnings literature, and is then tested on a real robot, the brushbot, whose dynamics is unknown, highly complex and nonstationary.
BibTex: @inproceedings{ohnishi2017online,
title={Online learning in L2 space with multiple {G}aussian kernels},
author={Ohnishi, M. and Yukawa, M.},
booktitle={IEEE Proc.~EUSIPCO},
pages={1594--1598},
year={2017}
}
2017
Workshops & Invited Talks
Title / Organizer
Presentation
Place
Year
Adaptive Safe Learning and Continuous-time Reinforcement Learning(Orginizer: Prof. Stefanos Nikolaidis, University of Southern California)
Invited Talk
University of Southern California @USA
2019
Continuous-time Value Function Approximation in Reproducing Kernel Hilbert Spaces(Orginizer: RIKEN AIP / Israeli universities/institutes)
Poster
Bar-Ilan Univ. @Tel Aviv
2018
Online Nonlinear Estimation via Iterative L2-Space Projections(Orginizer: RIKEN AIP / National University of Singapore)
Poster
National University of Singapore @Singapore
2018
Theses
Title / Degree
University
Year
Safety-aware Adaptive Reinforcement Learning with Applications to Brushbot Navigation [KTH DiVA]
Degree: M.S. in Electrical Engineering
Royal Institute of Technology, Sweden
Department: Automatic Control
2019
A Study on Hilbert Space Design: Online Learning and Reinforcement Learning
Degree: M.S. in Integrated Design Engineering
Keio University, Japan
Department: Electronics and Electrical Engineering
2019
Awards
Fellowships or Grants
Name
Organization
Month/Year
Research funding sponsored by Japan Science and Technology Agancy (JST) (2021-2022)
JST
06/2021
Travel grant awarded for our paper "Information Theoretic Regret Bounds for Online Nonlinear Control" presented
at NeurIPS 2020, Online.
Fellowship for the first academic year of my Ph.D. study (2019-2020). See here.
University of Washington
05/2019
Fellowship for the Ph.D. study abroad. This funding is expected to cover two years of my Ph.D. study (2020-2022). See here.
Funai foundation
11/2018
Travel grant awarded for our paper "Continuous-time Value Function Approximations in Reproducing Kernel Hilbert Spaces" presented
at NeurIPS 2018, Montreal, Canada.
NeurIPS foundation
10/2018
Scholarship awarded to selected Keio university students studying abroad.
Keio university
12/2017
Research grant for master students presenting their researches at international conferences. See here.
Keio university
07/2017
Travel grant awarded by the School of Electrical Engineering, Royal Institute of Technology, to selected students conducting their master thesis projects outside of Sweden. See here.
School of Electrical Engineering, KTH
07/2017
Research grant awarded for selected research projects related to Scandinavian countries. See here.
Scandinavia-Japan Sasakawa foundation
03/2017
Scholarship awarded to selected Keio university students studying abroad.
Keio university
12/2016
Academic awards
Name
Organization
Month/Year
Awarded to selected researchers (2022)
JST
03/2022
The best undergraduate research award in the field of information technology in Dept. Electronics and Electrical Engineering, Keio university
Dept. Electronics and Electrical Engineering, Keio university