HW1: An end-to-end data pipeline and analysis
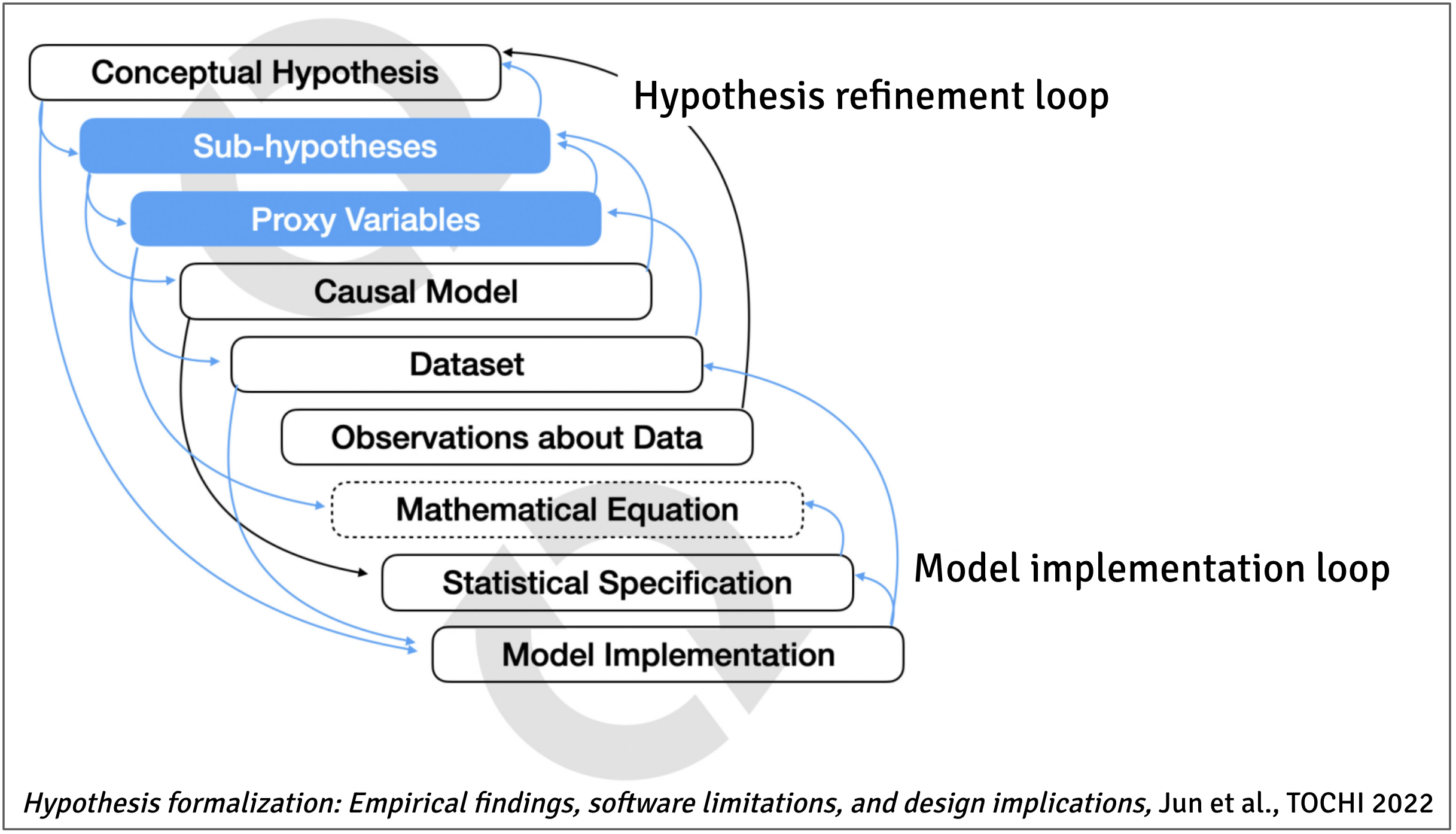
High-level goal
The high-level goal of this exercise is to develop an end-to-end data analysis pipeline in R, starting from real-world research questions and existing data.
Set up
This is an individual exercise!
This exercise involves four main steps:
- Conceptual modeling: defining the methodology (constructs of interest, proxy measures, etc.) and reasoning about validity and limitations.
- Data wrangling: cleaning and consolidating the data, which is coming from different data sources.
- Statistical analysis: analyzing the data with appropriate statistical methods to increase statistical and conclusion validity.
- Conclusions: contextualizing and interpreting the results.
You are free to use any IDE or editor, but we do require:
- The final deliverable (submission) is an executable notebook, with all code cells written in R.
- All four main steps are clearly labeled and documented in the submitted notebook.
- Executing the submitted notebook must successfully reproduce the results of your data analysis pipeline without manual intervention.
- Clean and concise code, with a consistent coding style and use of
tidyversepackages for data wrangling. - Adequate testing of data properties, data transformations, etc.
Getting help:
- Data: Ask general clarification questions on Ed (
[HW1] Data questionsthread). - Tidyverse: See the demos on the course website and the linked references. If you can’t find an answer, post a general question on Ed (
[HW1] Tidyverse questionsthread). - Stats: Ask general clarification questions on Ed (
[HW1] Stats questionsthread). - Solution-specific questions: Send the course staff a private Ed message (HW1 category).
- Data: Ask general clarification questions on Ed (
Recommended packages:
tidyverse: See the package descriptions and cheat sheets and the R for Data Science online book.assertthat: See the package description.effsize: See the package description.jsonlite: See the package description.
Background
Given a bug and commonly a set of tests, of which at least one test triggers the bug, Automated Program Repair (APR) aims to find a patch such that all tests pass. A plausible patch passes all tests, but may still be incorrect. A correct patch is plausible and satisfies the intended specification of the software system.
APR studies have extensively used the Defects4J benchmark. Here are some common observations and conjectures:
- APR tools are more successful for bugs of projects added in Defects4J v1.0 than for bugs of projects added in Defects4J v1.1 and v2.0.
- Weak tests are correlated with APR tools producing plausible yet incorrect patches.
- More complex bugs may be more difficult to patch automatically.
- APR tools may overfit to Defects4J v1.0 (compared to v1.1 and v2.0) but the reasons are unknown.
Instructions
Given the background on APR and the data set described below, your goal is to shed some light on possible explanations for observed differences in APR tool efficacy.
You are free to define your own research questions and hypotheses. You may find the following two high-level questions useful to guide you towards more precise research questions:
Are there key differences between v1.0 and v1.1/v2.0 of Defects4J, considering dimensions such as code/bug/test characteristics?
Is APR success associated with certain code/bug/test characteristics?
NOTE: Key grading aspects are design justifications and adequate testing of the analysis pipeline. Additionally, grading will consider the overall execution of the data analysis in the context of its scope. (In particular, a very simple analysis must be very well executed.)
Part 1: Methodology (30%)
State your research questions and hypotheses.
State constructs of interest and proxy measures.
Justify your choices and be explicit about CDA vs. EDA.
Discuss validity (in particular construct validity) and limitations of your analysis design.
Part 2: Data Wrangling (30%)
Consolidate all data files, and clean up and test the data.
Make sure to adequately test data properties and data transformations.
Add comments that link test assertions to data expectations and the methodology.
NOTE: This step should create a single tibble by adequately merging all five data files.
Part 3: Statistical Analysis (20%)
Select adequate statistical methods (incl. effect sizes).
Add comments that link the statistical methods to the methodology.
Make sure the notebook computes all results that inform the overall conclusions.
This comprehensive summary provides concrete examples for various statistical methods.
NOTE: We do not expect you to be an expert on statistical methods. Once you have defined your research questions and analysis design, feel free to engage the course staff in your hypothesis formalization process.
Part 4: Conclusions (20%)
Contextualize and interpret your results.
Answer your stated research questions.
Data set
The data set is derived from the following data sources and tools:
For simplicity and efficiency, the course staff have pre-processed and consolidated some of the raw data. The result of these pre-processing and consolidation steps are the 5 data files below.
Code-level information: code_stats.csv
PID: See the 17 project ids in Defects4J.BID: See the active bug ids in Defects4J.D4JVersionAdded: Defects4J version when the project and its bugs were added – 1.0, 1.1, or 2.0.ClocSrc: Result of running cloc over all non-test source files.ClocTest: Result of running cloc over all test source files.RelevantFiles: Number of files touched by any triggering test.PatchedFiles: Number of files patched by the bug fix.AllTests: Number of all test methods across all test source files.RelevantTests: Number of test methods that touch at least one patched file.TriggerTests: Number of test methods that trigger the bug.
PID and BID uniquely identify a bug.
Bug information: bug_stats.csv
PID: See the 17 project ids in Defects4J.BID: See the active bug ids in Defects4J.DelLines: Number of lines deleted by the bug fix.InsLines: Number of lines added by the bug fix.ModLines: Number of lines changed by the bug fix.FileName: Name of the buggy file.
PID, BID, and FileName uniquely identify a buggy file. (A bug may have more than 1 buggy file.)
Coverage information: coverage_stats.csv
PID: See the 17 project ids in Defects4J.BID: See the active bug ids in Defects4J.LinesTotal: Number of all lines across all files patched by the bug fix – line coverage.LinesCovered: Number of covered lines in across all files patched by the bug fix – line coverage.ConditionsTotal: Number of all conditions across all files patched by the bug fix – condition coverage.ConditionsCovered: Number of covered conditions across all files patched by the bug fix – condition coverage.
PID and BID uniquely identify a bug. (The code coverage analysis may have failed for some bugs.)
Mutation information: mutation_stats.csv
PID: See the 17 project ids in Defects4J.BID: See the active bug ids in Defects4J.MutantsTotal: Number of all mutants generated across all files patched by the bug fix.MutantsCovered: Number of covered mutants across all files patched by the bug fix.MutantsDetected: Number of detected mutants across all files patched by the bug fix.
PID and BID uniquely identify a bug. (The mutation analysis may have failed for some bugs.)
If you are unfamiliar with mutation analysis, you can think of: (1) the ratio of detected mutants to covered mutants as an indicator for test assertion strength, and (2) the ratio of covered mutants to all mutants as a code coverage measure (strongly correlated with line coverage).
APR results: apr_results.csv
tool: Name of APR tool – lower case.pid: Defects4J project id – lower case.bid: Defects4J bug id.patch_id: Patch id.is_correct: Patch correctness – Yes = Correct patch; No = Incorrect yet plausible patch (passes all tests).
tool, pid, bid, and patch_id uniquely identify a repair attempt that produced a patch.
Deliverables
- An executable notebook with all your code and analysis narrative. Acceptable notebook formats are:
- Rmarkdown: .Rmd
- Jupyter: .ipynb
Steps for turn-in
Upload the deliverables to Canvas.