Total Selfie: Generating Full-Body Selfies




Abstract
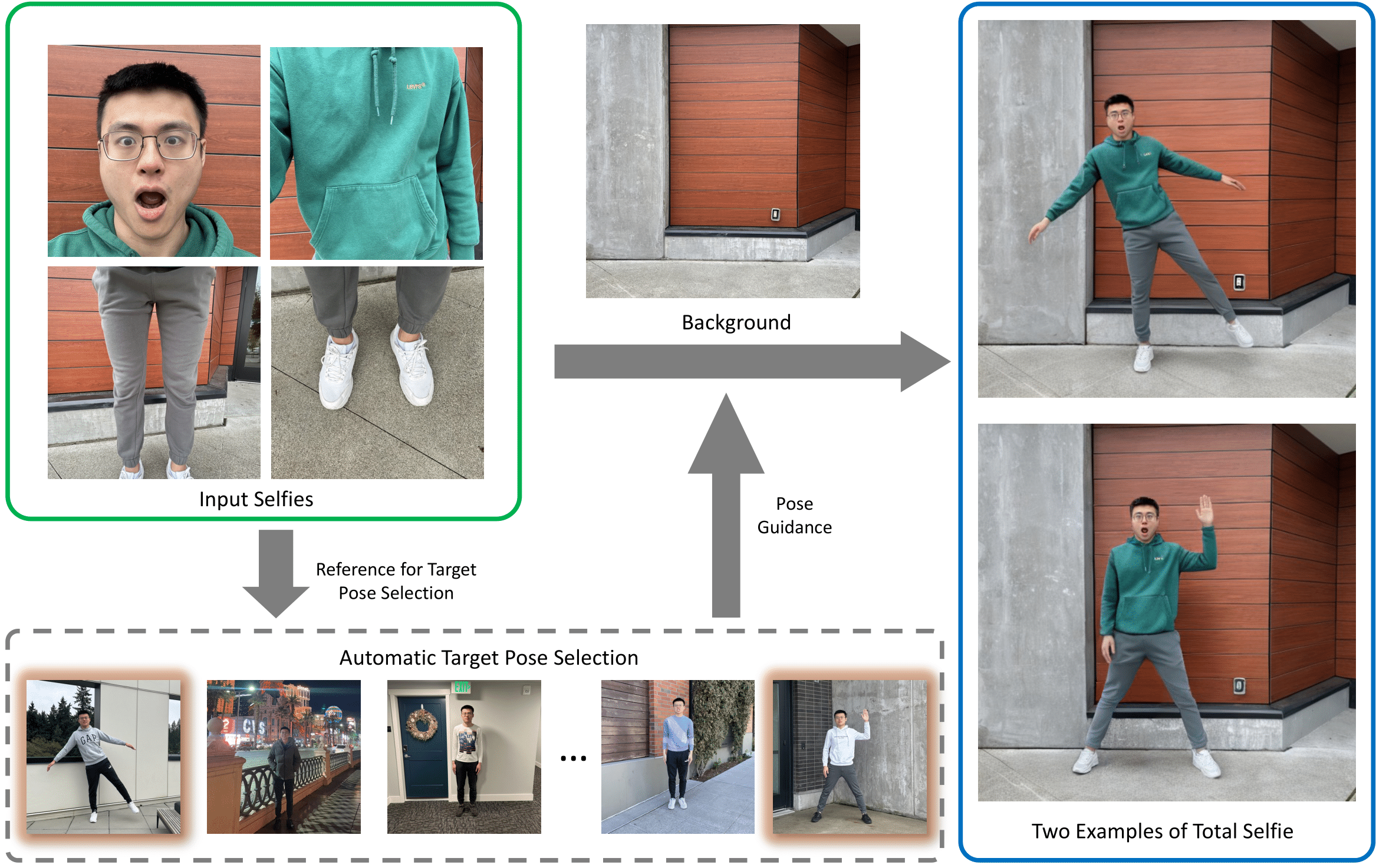
We present a method to generate full-body selfies from photographs originally taken at arms length. Because self-captured photos are typically taken close up, they have limited field of view and exaggerated perspective that distorts facial shapes. We instead seek to generate the photo some one else would take of you from a few feet away. Our approach takes as input four selfies of your face and body, a background image, and generates a full-body selfie in a desired target pose. We introduce a novel diffusion-based approach to combine all of this information into high-quality, well-composed photos of you with the desired pose and background.
Video
Total Selfie
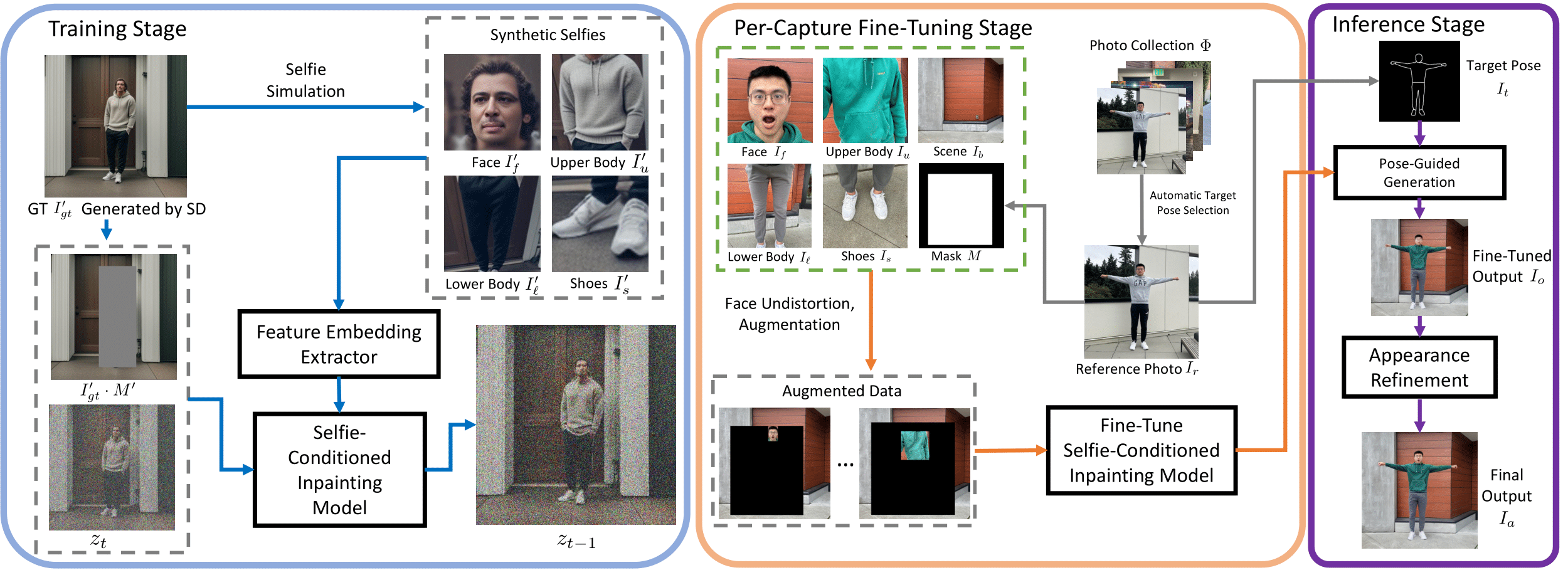
Overview of Total Selfie. First, we train a selfie-conditioned inpainting model based on a synthetic selfie to full-body dataset (blue box). Second, we fine-tune the trained model on a specific capture (orange box), and use it to produce a full-body selfie with the help of modified ControlNet (for pose) and appearance refinement (for face and shoes), visualized in the purple box. Note that, images in the green dashed box (inside the orange box) serve as input and conditional signals to the inpainting model, arrows omitted for simplicity.
Experiments
Results of Total Selfie

Results of Total Selfie. The second column shows the Canny Edge images detected from reference images (shown as insets). Regions inside yellow box of (c) are the masked regions. Total Selfie generates realistic, full-body images of different individuals with diverse poses and expressions against a variety of backgrounds, while preserving facial expression and clothing. The results are robust to selfies captured in different ways, such as those with one or two hands involved or from a downward-looking perspective (row 4), and with target pose images in outfits that differ somewhat from the input selfies..
Comparison with Baselines

Qualitative Comparison with baselines. Qualitative comparison with two best-performing baselines. For this comparison, we used Canny Edge of the real photo as target pose (inset of (f)). Our pipeline clearly outperforms baselines in terms of photorealism and faithfulness (zoom in for details, including faces and shoes). Note that, while the selfies, background image, and real photo were captured in the same session, variations in lighting conditions, auto exposure, white balance, and other factors may result in intensity and color tone differences. etc .
Ablation Study

Results for different modules of our pipeline. Background image omitted due to space; regions inside bounding box (c) are to be inpainted. The Canny Edge image in (b) is detected from the reference image, inset. Generating without fine-tuning (c) produces inaccurate outfit and identity. Through fine-tuning, the pipeline (d) generates correct outfit with reasonable shading and clothing details (\eg, wrinkles on upper cloth), but with wrong identity. With appearance refinement, the full pipeline (e) yields high-quality full-body selfies.
Limitaions
Total Selfie has several limitations: (1) While our method generally yields a harmonized output (b), the shading of the body may not precisely align with that in the actual photo (c). (2) Our method cannot accurately generate hard shadows of a person under strong sunlight since inferring the sun's direction and scene geometry solely from the background is difficult.

Acknowledgements
This work was supported by the UW Reality Lab, Meta, Google, OPPO, and Amazon. Special thanks to Jingyi Lin, Jingwei Ma, Kunbo Ding, Qichen Fu, Bohan Chen, Yu Pan, Yuqun Wu, Yuhan Fang, and Mengyi Shan, for their support and help with collecting data.