
![[Dan]](drkp_orig.jpg)
Dan R. K. Ports
Current projects
Distributed Systems for the Data Center
Distributed systems are traditionally designed independently from the underlying network, making worst-case assumptions about its behavior. Such an approach is well-suited for the Internet, where one cannot predict what paths messages might take or what might happen to them along the way. However, many distributed applications are today deployed in datacenters, where the network is more reliable, predictable, and extensible. We argue that in these environments, it is possible to co-design distributed systems with their network layer, and doing so can offer substantial benefits.
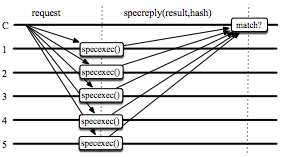
Our recent work uses this approach to improve state machine replication protocols, which are important both as the standard mechanism for ensuring availability of critical datacenter services and as the basis for distributed storage systems. The first project uses network-level techniques to provide a Mostly-Ordered Multicast primitive (MOM) with a best-effort ordering property for concurrent multicast operations. We use this primitive to build Speculative Paxos, a new replication protocol that relies on the network to order requests in the normal case, while still remaining correct if messages are delivered out of order. By leveraging the datacenter network properties, Speculative Paxos can provide substantially higher throughput and lower latency than the standard Paxos protocol.
High-Performance Transactional Storage

Transactional Application Protocol for Inconsistent Replication, or TAPIR, is a new protocol for linearizable distributed transactions built atop a new replication protocol that provides no consistency guarantees. TAPIR eliminates expensive coordination from the replication layer, yet provides the same transaction model and consistency semantics as existing systems like Spanner. It can commit transactions in a single round-trip, greatly improving both latency and throughput relative to existing systems.
Claret

Interactive distributed applications are difficult to scale because the high degree of writes and update operations and the highly skewed access patterns exhibited by real-world systems lead to high contention in datastores. There is often sufficient concurrency in these applications to scale them without resorting to weaker consistency models, but traditional concurrency control mechanisms operating on low level operations cannot detect it. The core idea behind Claret is to allow programmers to express application semantics, such as which transactions can commute with one another, to the datastore so that it can use that extra concurrency to improve performance.
Claret is the first datastore to use ADTs to improve performance of distributed transactions; optimizations include transaction boosting, phasing, and operation combining. On a transaction microbenchmark, Claret's ADT optimizations increase throughput by up to 49x over the baseline concurrency control and even up to 20% better than without transactions. Furthermore, Claret improves peak throughput on benchmarks modeling real-world high-contention scenarios.
Predictable Low-Latency Systems
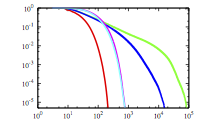
Modern datacenter applications struggle with the need to access thousands of servers while still providing a fast response time to the user. In these situations, the user's overall request is not complete until the slowest of the subrequests has completed, making it important to design network services that offer not just low latency but predictable latency.
We are developing techniques for building systems that offer predictable response time. At the operating system level, we have conducted an extensive measurement study to identify factors that can cause even a completely deterministic application to have occasional requests that take several orders of magnitude longer than expected. Using a set of modifications to the kernel scheduler, network stack, and application architecture, we can reduce the tail latency to within a few percent of optimal.
Arrakis

Arrakis is a radical restructuring of the traditional operating system inspired by a concept from high-speed network routers: we split the operating system into a separate control plane and data plane. Leveraging recent virtualized I/O hardware technology for network and storage device access, we move the operating system off the I/O data path by providing safe, direct access to hardware devices at user level. The OS kernel is needed only on the data plane, to configure which data paths are allowed and what resource limits should be enforced in hardware.
Agate

Today’s mobile devices sense, collect, and store enormous amounts of personal information, while our favorite applications let us share that information with family and friends. We trust these systems and applications with our sensitive data and expect them to maintain its privacy. As we have repeatedly witnessed, this trust is often violated due to bugs, confusing privacy controls, or an application’s desire to monetize personal data.
Agate is a trusted distributed runtime system that: (1) gives users the power to define privacy policies for their data, and (2) enforces those policies without needing to trust applications or their programmers. Agate combines aspects of access control and information flow control to ensure that applications executing across mobile platforms and cloud servers meet our privacy expectations.
Persistent Process Containers for Non-Volatile Main Memory Systems

Emerging non-volatile memory technologies such as phase-change memory, spin-torque memory, and flash-backed DRAM blur the line between volatile memory and persistent storage, challenging a distinction that has existed since the earliest days of operating systems. Our group is rethinking fundamental operating system abstractions for this new environment.
Our current work is exploring process models for this environment, where the state of a running process and an executable on disk do not need to differ. We are organizing applications around a persistent process container abstraction that encapsulates all application state. Process containers are persistent, surviving OS and hardware crashes, and can be rolled back to earlier states.
Past projects
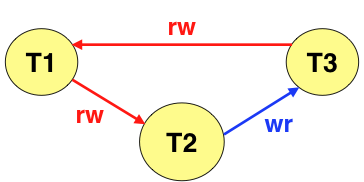
Aeolus
Aeolus is a platform for building secure distributed applications using the decentralized information flow control model. Aeolus differs from previous information flow control systems in that it is intended to be easier to understand and use. It incorporates a new, simpler security model that combines principal-based authority management with thread-granularity information flow tracking, and provides new abstractions that support common design patterns in secure application design. Aeolus is implemented as a Java library, using a new lightweight isolation mechanism to support controlled sharing between threads.
Overshadow
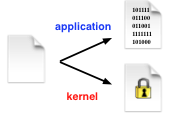
Commodity operating systems are complex and prone to compromise. Overshadow is a virtual-machine-based system for protecting the privacy and integrity of unmodified applications even when the OS they run on is completely compromised. Overshadow uses multi-shadowing, a new technique that uses the hypervisor to provide the application with a normal view of its resources, but the OS with an encrypted view. This allows the operating system to remain responsible for managing application resources, without being able to read or modify their contents, permitting a smaller trusted computing base.
Later work considered the security implications of malicious OSes, an analysis relevant not just to Overshadow but also to other systems that protect security-critical portions of applications from the OS. Previous work focused on CPU and memory isolation; our analysis instead examined higher-level semantic attacks, where malicious misbehavior by various OS components can undermine application security, and proposed an architecture for mitigating them.
Census
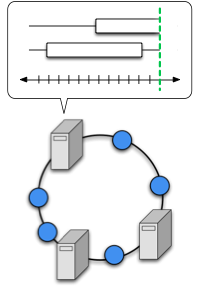
Census is a platform for building large-scale distributed applications that provides a membership service and a multicast mechanism. The membership service provides every node with a consistent view of the system membership, which may be global or partitioned into location-based regions. Census distributes membership updates with low overhead, propagates changes promptly, and is resilient to both crashes and Byzantine failures.
Census is designed to provide this consistent membership abstraction at very large scale, e.g. multi-site datacenters. It does this using a novel multicast mechanism that is closely integrated with the membership service.
Arpeggio
Arpeggio is a peer-to-peer file-sharing network based on the Chord distributed hash table. It performs search queries based on file metadata efficiently by using a distributed keyword-set index, augmented with index-side filtering. Arpeggio also introduces new techniques for tracking the availability of data without inserting the data itself into the DHT, and for using information in the index to improve the availability of rare files.