Gradient Descent
Gradient descent is a very popular optimization method. In its most basic form, we have a function that is convex and differentiable. We want to find:
The algorithm is as follows. Choose an initial , and repeat until some convergence criterion:
What is it doing?
At each iteration, consider the following approximation:
Note that is a linear approximation of , using the gradient at point . For example, take , and let's approximate it at the point using its gradient:
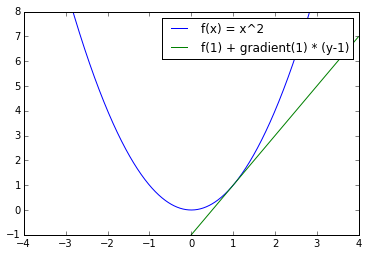
Note as well that is a term that penalizes points away from , with weight , so that when gets smaller, we pay more to move away from the current point:
Summing the two terms, we have a quadratic approximation to the function at point :
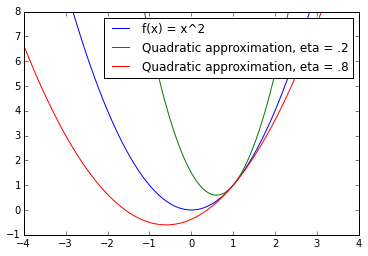
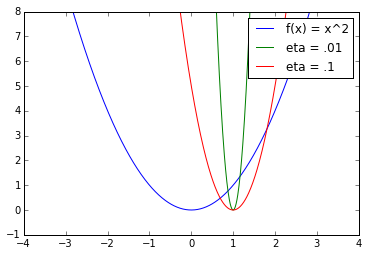
We will now show that gradient descent is in fact minimizing this quadratic approximation at each step. Before we do this, we can notice in the previous picture how important it is to get the right step size . In that case, if , we will clearly go past the minimum of the function we are trying to optimize as we take one step from . Now, let's see what the minimum to the quadratic approximation is:
It is easy to see that this function is minimized when , which is exactly the equation for the value of .
Convergence Analysis
We will prove a convergence bound for when the gradient of the function is Lipschitz continuous, i.e.:
We already assumed that the function is convex and differentiable, i.e. ,:
First, we will prove that the following holds for any x,y:
Or equivalently:
To prove this, we will use an auxiliary function . Note that
We substitute the above to get :
Now we will use the above for iteration with . To simplify notation, let and .
Now, take . This implies . Plugging this in the inequality above:
Note that we just proved that we are actually doing a descent - meaning that the function is decreasing (or staying the same) with each step we take, since and .
Now we will use the convexity of . Specifically, take to be the optimal solution to the problem. We can use the following linear approximation at (from the definition of convexity):
Which equivalently is:
Now that the inequality is in the right direction, we can directly plug it into (5):
The reason we put in that particular form is because we will manipulate the term inside the parenthesis. Note the following:
Let the term inside the parenthesis of (6) be . It is clear that , and thus . From this, we get a modified form of (6):
Now, all of this was just for a particular iteration. Now we will bound the sum over the difference between the of each iteration and the optimal :
Now, all of this was just for a particular iteration. Now we will bound the sum over the difference between the of each iteration and the optimal :
This is our bound. Notice what it tells us: if the assumptions are met, and we use an appropriate constant stepsize, the distance between the loss at iteration and the optimum goes down at a rate that goes down at (linear in ), where the constant depends on how far our initial guess is from the optimal parameters.
What is an appropriate constant stepsize? Smaller than , meaning that we can take larger stepsizes if the Lipschitz constant of the gradients is small - which makes sense, because that would mean that the gradients can't be too big, which could cause us to overshoot.
We did a lot of steps, but notice the most important ones:
- In (3), we bounded how much can change around any point , using the Lipschitz constant.
- In (5), we showed that we are improving on the objective at each iteration, at a particular rate
- From there, we just did math to see what happens after iterations