Is Logistic Regression a linear classifier?
A linear classifier is one where a hyperplane is formed by taking a linear combination of the features, such that one 'side' of the hyperplane predicts one class and the other 'side' predicts the other. For logistic regression, we have that
We would predict positive if , or equivalently:
Taking logs on both sides (note that the log function is monotonically increasing, meaning that it preserves the order of inputs, and thus inequalities are still valid), we have:
Thus, we see that the decision boundary is given by the plane .
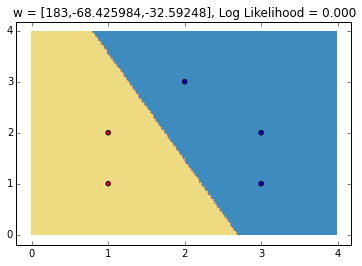
Some example decision boundaries
Note that on the second figure, the log likelihood is higher. This is expected, as the decision boundary separates the data points better than the first one.
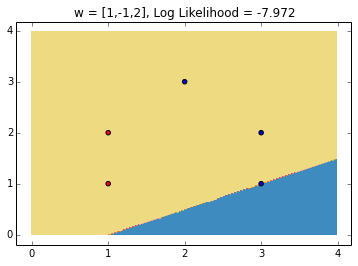
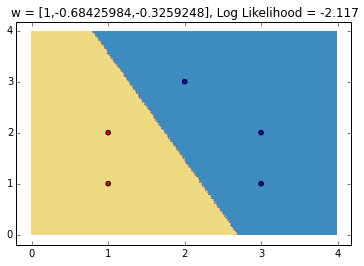
The need for regularization
Note in the figure above that the log likelihood is not exacly 0, which would be the case if the likelihood was exactly one, meaning we fit the data perfectly. This is because the log likelihood depends not only on the decision boundary, but on the 'confidence' of each prediction. Also note that we can increase the confidence while maintaining the same decision boundary, by simply scaling up the parameters of w. Note that if the data is linearly separable, the weights would go to infinity. In general, not controling the norm of w will lead to overfitting, which is why we need regularization.