Block Entropy Analysis of the
[September
2010]
This
page provides additional information for the block entropy plot in Entropy, the Indus script, and language and our IEEE Computer article.
The figure below (adapted
from our IEEE Computer article (Rao, 2010))
plots the block entropies of various types of symbol sequences as the block
size is increased from N = 1 to N = 6 symbols. Block entropy generalizes
Shannon entropy (
![]()
where ![]() are the probabilities
of sequences (blocks) of N symbols. Thus, for N = 1, block entropy is simply
the standard unigram entropy and for N = 2, it is the entropy of bigrams. Block
entropy is useful because it provides a measure of the amount of flexibility
allowed by the syntactic rules generating the analyzed sequences (Schmitt &
Herzel, 1997): the more restrictive the rules, the smaller the number of
syntactically correct combinations of symbols and lower the entropy.
Correlations between symbols are reflected in a sub-linear growth of HN with N (e.g., H2
< 2H1).
are the probabilities
of sequences (blocks) of N symbols. Thus, for N = 1, block entropy is simply
the standard unigram entropy and for N = 2, it is the entropy of bigrams. Block
entropy is useful because it provides a measure of the amount of flexibility
allowed by the syntactic rules generating the analyzed sequences (Schmitt &
Herzel, 1997): the more restrictive the rules, the smaller the number of
syntactically correct combinations of symbols and lower the entropy.
Correlations between symbols are reflected in a sub-linear growth of HN with N (e.g., H2
< 2H1).
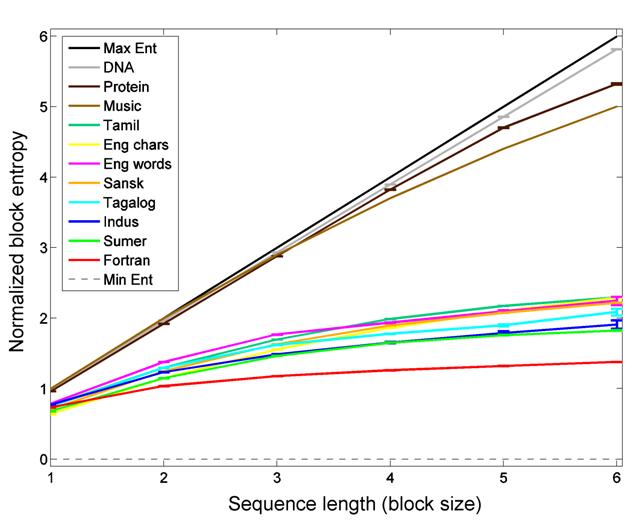
Figure 1: Block entropy scaling of the
The plot shows that the block entropies of the
These block entropies were estimated using a Bayesian
entropy estimation technique known as the NSB estimator (Nemenman et al., 2002), which has been shown to
provide good estimates of entropy for undersampled discrete data. We used this
technique to counter the relatively small sample size of the
The NSB estimator can be downloaded from here. The NSB parameter values
used for the plot above were: qfun=2 (Gauss
integration), todo = 1 (nsb integration on), precision=0.1.
Details regarding the datasets analyzed can be found in the supplementary
information in (Rao et al., 2009).
The Tagalog data comprised of text from three books (Ang Bagong Robinson (Tomo
1), Mga Dakilang Pilipino, Ang Mestisa). The values for music in the plot are
from (Schmitt & Herzel, 1997).
An alternate technique for estimating block entropies is
given in (Schmitt & Herzel, 1997). A figure similar to our plot above but
with data for DNA, music, English, and Fortran can be found in (Schmitt &
Herzel, 1997; Figure 8). Their technique however does not provide an estimate
of the standard deviation of the computed entropy value.
Similarity in entropy scaling (as in the figure
above) by itself is not a sufficient
condition to prove that the
References
Nemenman, Ilya, Fariel Shafee and William Bialek.
2002. Entropy and inference, revisited. Advances
in Neural Information Processing Systems 14, MIT Press. http://xxx.lanl.gov/abs/physics/0108025
Rao, Rajesh, Nisha Yadav, Mayank Vahia, Hrishikesh
Joglekar, R. Adhikari and Iravatham Mahadevan. 2009. Entropic evidence for
linguistic structure in the
PDF with supplementary information: http://www.cs.washington.edu/homes/rao/ScienceIndus.pdf
Rao,
Rajesh. 2010. Probabilistic analysis of an ancient undeciphered script. IEEE Computer, 43(4): 76-80.
http://www.cs.washington.edu/homes/rao/ieeeIndus.pdf
Rao, Rajesh, Nisha Yadav, Mayank Vahia, Hrishikesh
Joglekar, R. Adhikari and Iravatham Mahadevan. 2010. Entropy, the
http://www.cs.washington.edu/homes/rao/IndusCompLing.pdf
Schmitt, Armin and Hanspeter Herzel. 1997. Estimating
the entropy of DNA sequences. J. Theor.
Biol., 1888: 369-377.
Shannon,
Claude. 1948. A mathematical theory
of communication. Bell System Technical
Journal, 27:379-423, 623-656.
Siddharthan, Rahul. 2009. More
http://horadecubitus.blogspot.com/2009/05/more-indus-thoughts-and-links.html
Yadav N,
Vahia MN, Mahadevan I, Joglekar H (2008) A statistical approach for pattern
search in