Entropy, the Indus
Script, and Language:
A Reply to R. Sproat
Rajesh P. N. Rao,
Nisha Yadav, Mayank N. Vahia, Hrishikesh Joglekar,
R. Adhikari, and Iravatham Mahadevan1
To appear in Computational Linguistics 36(4), 2010.
Printable PDF preprint is here.
1 Introduction
In a recent Last Words column [ Sproat2010],
Richard Sproat of the Oregon Health and
2 The
Indus Script Debate
The Indus script
refers to the approximately 4000 inscriptions on seals, miniature tablets,
pottery, stoneware, copper plates, tools, weapons, and wood left behind by the
Indus civilization, which flourished ca. 2600-1900 BCE in
In 2004, Sproat
and colleagues published in the Electronic Journal of Vedic Studies an
article whose title makes the unconditional pronouncement "The collapse of
the
[ Sproat2010]
states that their arguments "have been accepted by many archaeologists and
linguists" without citing who these "many archaeologists and
linguists" are. In fact, a number of respected scholars, not just those
who have "spent most of their careers trying to decipher the symbols"
[ Sproat2010],
have voiced strong disagreement [
Possehl2004,
Kenoyer2004,
Mahadevan2009]. Several have published point-by-point
rebuttals [ Parpola2005,
Vidale2007, McIntosh2008]. Parpola, who is widely regarded as
the leading authority on the
3 Fallacies Resolved
Under
a section entitled "The Fallacies," [
Sproat2010] describes a result from our article in Science
[ Rao et al. 2009a]
which presents evidence against the thesis of [ Farmer, Sproat, and
Witzel2004]. In
our article, we show that the conditional entropy of the
To set up his criticism of our work, [ Sproat2010] presents Figure 1A from our Science paper but never mentions the results presented in Figure 1B in the same paper. Nor does he describe our more recent block entropy result [ Rao2010b], even though he cites this paper (this new result extends the conditional entropy work). Both of these results include data from demonstrably nonlinguistic sequences, namely, DNA, protein sequences, and Fortran code. To present our work as "simple experiments involving randomly generated texts" is, to say the least, a gross misrepresentation of our work.
To
correct this misrepresentation, we present in Figure 1(b) the block entropy result (adapted from [ Rao2010b]). Block entropy generalizes
|
(1) |
where pi(N) are the probabilities of sequences (blocks) of N symbols. Thus, for N = 1, block entropy is simply the standard unigram entropy and for N = 2, it is the entropy of bigrams. Block entropy is useful because it provides a measure of the amount of flexibility allowed by the syntactic rules generating the analyzed sequences [ Schmitt and Herzel1997]: the more restrictive the rules, the smaller the number of syntactically correct combinations of symbols and lower the entropy. Correlations between symbols are reflected in a sub-linear growth of HN with N (e.g., H2 < 2H1).
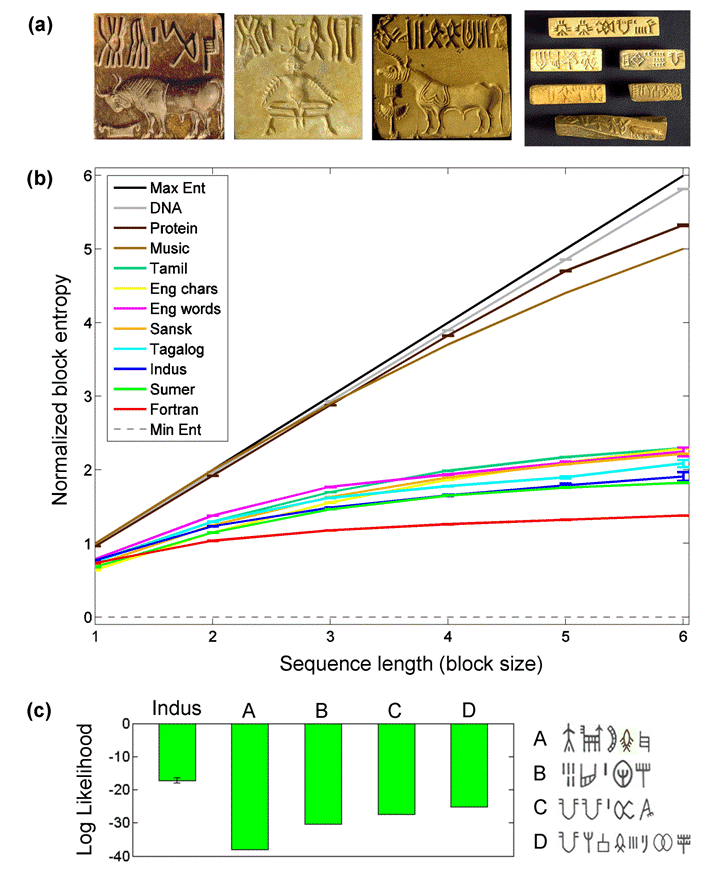
Figure
1: (a) Examples of the
Figure 1(b) plots the block entropies of various types of symbol sequences as the block size is increased from N = 1 to N = 6 symbols. To counter the problems posed by the small sample size of the Indus corpus (about 1,550 lines of text and 7,000 sign occurrences), we employed a Bayesian entropy estimation technique known as the NSB estimator [ Nemenman, Shafee, and Bialek2002], which has been shown to provide good estimates of entropy for undersampled discrete data. Details regarding the NSB parameter settings and the datasets used for Figure 1(b) can be found here [ Rao2010a].
As seen in Figure 1(b),
the block entropies of the
Does the similarity in block entropies with
linguistic systems in Figure 1(b) prove
that the
However, Sproat, Liberman, and Shalizi (in a blog
by [
Liberman2009]) and Sproat at
EMNLP'09 undertake the exercise of knocking down the strawman
("similarity in conditional entropy by itself implies language") and
present artificial counterexamples (e.g., having Zipfian
distribution) with conditional independence for bigrams [
Sproat2010]. First, such an exercise misses the
point: as stated above, we do not claim that entropic similarity by itself is a
sufficient condition for language. Second, these "counterexamples"
ignore the fact that the unigram and bigram entropies are markedly different
for both the
[
Sproat2010] criticizes our classification of
"Type 1" and "Type 2" nonlinguistic systems (corresponding
to systems near Max Ent and
Min Ent respectively in Figure 1(b)) saying these do not characterize any
natural nonlinguistic systems. It is clear from Figure 1(b) that there do exist
natural "Type 1" nonlinguistic sequences (DNA, protein sequences).
The analogous result for conditional entropy was given in Figure 1B in [
Rao2010b] which was omitted in [
Sproat2010]. As for "Type 2" systems, [
Vidale2007] provides a number of examples of ancient
nonlinguistic systems from Central and South Asia whose properties are in line
with such systems. Section 6 below discusses these systems as well as
the specific cases of Vinča and kudurru sequences mentioned in [
Sproat2010]. Sproat,
Farmer, and colleagues have objected to the use of artificial datasets in [ Rao et al. 2009a] to demarcate the Max Ent and Min Ent limits:
this objection is a red herring and does not change the result that the
We
conclude by noting here that the extension of our original conditional entropy
result to block entropies directly addresses the objections of [ Pereira2009]
who stressed the need to go beyond bigram statistics, which Figure 1(b) does for N up to 6. Beyond N = 6, the
entropy estimates become less reliable due to the small sample size of the
4 Inductive Inference
The correct way of interpreting the block entropy result in Figure 1(b) (and likewise the conditional entropy result) is to view it within an inductive framework (rather than in a deductive sense as Sproat and others do in [ Liberman2009]). Given that we cannot answer the ontological question "Does the Indus script represent language?" without a true decipherment, we formulate the question as an epistemological problem, namely, one of estimating the posterior probability of the hypothesis HL that an unknown symbol sequence represents language, given various properties P1, P2,P3,… of the unknown sequence. Using a Bayesian formalism, the posterior P(HL | P1, P2, P3, …) is proportional to P(P1,P2, P3,…| HL)P(HL).
Building on prior work [ Hunter1934, Knorozov1968, Mahadevan1977, Parpola1994], we have sought to quantitatively characterize various properties P1, P2, P3,… of the Indus script [ Yadav et al. 2008a, Yadav et al. 2008b, Rao et al. 2009a, Rao et al. 2009b, Yadav et al. 2010, Rao2010b]. In each case, we compare these properties with those of linguistic systems to ascertain whether the property tilts the evidence towards or away from the linguistic hypothesis HL.
We find these properties to be:
- Linearity: The Indus texts are linearly written, like the vast majority of linguistic scripts (and unlike nonlinguistic systems such as medieval heraldry, Boy Scout merit badges, or highway/airport signs, systems frequently mentioned by Sproat and colleagues);
- Directionality: There is clear evidence for directionality in the script: texts were usually written from right to left, a fact that can be inferred, for example, from a sign being overwritten by another on its left on pottery [ Lal1966]. Directionality is a universal characteristic of linguistic systems but not necessarily of nonlinguistic systems (e.g., heraldry, Boy Scout badges);
- Use of Diacritical Marks:
- Zipf-Mandelbrot Law: The script obeys the Zipf-Mandelbrot law, a power-law distribution on ranked data, which is often considered a necessary (though not sufficient) condition for language [ Yadav et al. 2010];
- Syntactic Structure: The script exhibits distinct language-like syntactic structure including equivalence classes of symbols with respect to positional preference, classes of symbols that function as beginners and enders, symbol clusters that prefer particular positions within texts, etc. [ Hunter1934, Parpola1994, Yadav et al. 2008a, Yadav et al. 2008b]. This structure is evident in both short texts as well as longer texts that are up to 17 symbols long;
- Diverse usage: The script was used on a wide range of media (from seals, tablets and pottery to copper plates, tools, clay tags, and at least one large wooden board), suggesting a diverse usage similar to linguistic scripts, and unlike nonlinguistic systems such as pottery markings, deity symbols on boundary stones, etc. whose use is typically limited to one type of medium;
- Use
in Foreign Lands: Indus texts have been discovered as far west as
Mesopotamia and the
Note that while one may find a nonlinguistic system that exhibits one of these properties (e.g., Zipfian distribution) and another that exhibits a different property (e.g., ligaturing), it would be highly unusual for a nonlinguistic system to exhibit a confluence of all of the above properties.
To the above properties, we add the property
in Figure 1(b) that
the
To claim to have "proof" of the nonlinguistic thesis [ Farmer, Sproat, and Witzel2004,pages 34 & 37],[ Farmer2005] would amount to showing a posterior probability of zero for the linguistic hypothesis. This is clearly not possible given our current state of knowledge about the script and the lack of an accepted decipherment.
Could the result in Figure 1(b) be an artifact of our particular entropy estimation method? We do not think so. A similar block entropy result was obtained independently by [ Schmitt and Herzel1997] using an entirely different entropy estimation method (see Figure 8 in their paper). The overall result is also confirmed by other methods, as discussed by Schmitt and Herzel: "This order-DNA, music, human language, computer language-when ordered by decreasing entropy, is confirmed by the calculation of the Lempel-Ziv complexity [ Lempel and Ziv1976] which also serves as an estimation of the entropy of the source" [ Schmitt and Herzel1997,page 376].
5 Comparison with Ancient Nonlinguistic Systems
Sproat contends that results such as the similarity in entropy scaling in Figure 1(b) are "useless" without analyzing a sizeable number of "ancient nonlinguistic systems" [ Sproat2010]. As mentioned earlier, Sproat ignores the fact that the results already include nonlinguistic systems: DNA and protein sequences (perhaps the two "most ancient" nonlinguistic systems!) as well as man-made sequences (Fortran code and music in Figure 1(b)).
We
believe entropic results such as Figure 1(b) to be both interesting and useful. An
analogy may be apt here: If, in the dim surroundings of a jungle, you notice
something moving and then spot some stripes, your belief that what is lurking
is a tiger will likely go up, even though it could also be a zebra, a man
wearing a tiger costume, or any of a number of possibilities. The observation
you made that the object under consideration has stripes is certainly not
"useless" in this case, just because you haven't ascertained whether
antelopes or elephants in the jungle also have stripes! In other words, we now
know that various types of symbol sequences, from natural sequences such as DNA
and proteins to man-made systems such as music and Fortran,
occupy quite different entropic ranges compared to linguistic systems
(Figure 1(b); Figure 8 in [ Schmitt
and Herzel1997]). Given this knowledge, the finding that
Indus sequences occupy the same entropic range as linguistic sequences, while
not proving that the
6 Countless Non-Linguistic Sign Systems?
Sproat
and colleagues have stated that the properties observed in the
Another nonlinguistic system mentioned in [ Sproat2010] is the
Vinča sign system, which refers to the markings
on pottery and other artifacts from the Vinča
culture of southeastern
"Neither the order nor the direction of the signs in these (sign) groups is generally determinable: judging by the frequent lack of arrangement, precision in the order probably was unimportant…Miniature vessels also possess sign-like clusters (Figure 12.2j), which are characteristically disarranged."
This contradicts [ Sproat2010] and suggests that the Vinča system, if it indeed lacks precision in the order of signs, would be closer to the maximum entropy (Max Ent) range than to the linguistic scripts in Figure 1(b). The actual amount of lack of precision unfortunately cannot be quantified in entropic terms because a large enough data set of Vinča sequences does not exist.
Sproat also draws attention to the carvings of deities on Mesopotamian boundary stones known as kudurrus. He declares that our statement regarding kudurru deity sequences obeying rigid rules of ordering compared to linguistic scripts is "clearly false." To shed more light on this issue, we cite here the work of several scholars in this field. Slanski, in a recent in-depth study of the form and function of kudurrus, states [ Slanski2003,page 163]:
"Hierarchical deployment of the divine symbols. [ Seidl1989] observed that, to a certain extent, the divine symbols were deployed upon the Entitlement narûs (kudurrus) according to the deities' relative positions in the pantheon. The symbols for the higher gods of the pantheon…are generally found upon or toward the top and most prominent part of the monument. Deities lower in the pantheon are deployed toward the bottom of the relief field."
A similar statement on the hierarchical ordering of symbols on kudurrus can be found in [ Black and Green1992,page 114]. The reader will probably agree that a system with even a rough hierarchical ordering among its symbols is more rigid than most linguistic systems. Linguistic systems have no such hierarchy imposed on characters or words, and there is considerable flexibility in where such symbols may be placed within a sequence. Therefore, as originally suggested in [ Rao et al. 2009a], we expect the entropy of the kudurru sequences to be lower than linguistic systems and perhaps slightly above the minimum entropy (Min Ent) range in Figure 1(b). Again, the actual entropy values cannot be estimated because, as admitted in [ Sproat2010], a large enough data set of kudurru sequences does not exist.
[ Sproat2010] says
that no one has done the "legwork" of putting together a large data
set of ancient nonlinguistic systems. This ignores the work of [ Vidale2007], who
did put together a set of 10 such systems. Vidale
questions the relevance of the nonlinguistic systems suggested by Sproat and colleagues since they are neither of the same
time period nor from the same geographical region as the
Are the kind of positional regularities found
in the
7 Implications of the Linguistic versus Nonlinguistic Hypotheses
If the
If, on
the other hand, as Sproat and colleagues propose, the
script merely represents religious or political symbols, one is hard pressed to
explain: (1) how and why were sequences of such symbols, with syntactic rules entropically similar to linguistic scripts (Figure 1(b)), used in trade in a manner strikingly
similar to other literate Bronze age
cultures? and (2) why did the
8 Conclusion
A large number of identification problems are amenable to statistical tests, and represent perhaps the only way to solve these problems. Practical examples include separating email from spam and recognizing faces in digital camera images. Even though we may not have a perfect test for any of these problems, the statistical methods that are used can be quite useful, even if they are fallible (we all rely on spam detectors for email even if they occasionally let a spam email through; we do not discard these detectors as "useless"). An important goal of our work [ Rao et al. 2009a, Rao et al. 2009b, Rao2010b, Yadav et al. 2010] has been to develop better statistical tests for linguistic systems. As with other statistical tests, it would be foolhardy to expect that a single such test is infallible, as assumed by Sproat and others in their quest to find "counterexamples" [ Sproat2010]. The observation that a single statistical test by itself is insufficient was the primary motivation for the inductive framework adopted in our research, where we apply a range of tests and estimate the posterior probability that an unknown sequence represents language (Section 4).
In the concluding remarks of his Last Words column, Sproat says it is not clear if editors of prominent science journals "even know that there are people who spend their lives doing statistical and computational analyses of text" [ Sproat2010]. We find such a statement surprising because it fails to acknowledge both the impressive achievements of the field of computational linguistics in recent years and the wide coverage of these accomplishments in the popular press ([ Fletcher2010] and [ Lohr and Markoff2010], to give two recent examples).
Computational
linguistics is playing an important role in our understanding of ancient
scripts [ Koskenniemi1981,
Knight and Yamada1999, Rao et al. 2009a, Rao
et al. 2009b, Yadav
et al. 2010, Snyder, Barzilay,
and Knight2010].
Rather than representing a "misuse of the methods of the field of
computational linguistics" [
Sproat2010], techniques from the field are providing
new insights into the structure and function of undeciphered
scripts such as the
References
Black, Jeremy and Anthony Green.
1992. Gods, Demons and Symbols of Ancient
Boy Scouts of
Farmer, Steve. 2005. Simple proof
against the '
http://www.safarmer.com/indus/simpleproof.html.
[ Farmer, Sproat, and Witzel2004]
Farmer, Steve, Richard Sproat, and Michael Witzel. 2004.
The collapse of the
Fletcher, Owen. 2010. Microsoft mines web to hone language tool. Wall Street Journal, August 3.
http://online.wsj.com/article/SB10001424052748703545604575406771145298614.html.
Hunter, Gerald. 1934. The
Script of
Kenoyer, Mark. 2004. Quoted in (Lawler 2004), page 2026.
Knight, Kevin and Kenji Yamada. 1999. A computational approach to deciphering unknown scripts. Proc. of ACL Workshop on Unsup. Learning in Natural Lang. Processing.
Knorozov,
Yuri et al. 1968. Proto-Indica: Brief Report on
the Investigation of the Proto-Indian Texts.
Koskenniemi,
Kimmo. 1981. Syntactic methods in the study of the
[ Koskenniemi, Parpola, and Parpola1970]
Koskenniemi, Seppo, Asko Parpola, and Simo Parpola. 1970. A method to classify characters of unknown ancient scripts. Linguistics, 61:65-91.
The
Lal, B. B. 1966. The direction of writing in the Harappan script. Antiquity, XL:52-55.
[ Lee, Jonathan, and Ziman2010]
Lee, Rob, Philip Jonathan, and
Pauline Ziman. 2010. Pictish
symbols revealed as a written language through application of
Lempel, Abraham and Jacob Ziv. 1976. On the complexity of finite sequences. IEEE Transactions on Information Theory, 22:75-81.
Liberman,
Mark. 2009. Conditional entropy and the
http://languagelog.ldc.upenn.edu/nll/?p=1374.
Lohr, Steve and John Markoff. 2010. Computers learn to listen, and some talk back. New York Times, June 24. http://www.nytimes.com/2010/06/25/science/25voice.html.
Mahadevan,
Iravatham. 1977. The
Mahadevan,
Iravatham. 2009. The
http://www.hindu.com/mag/2009/05/03/stories/2009050350010100.htm.
McIntosh, Jane. 2008. The
ancient
[ Nemenman, Shafee, and Bialek2002]
Nemenman, Ilya, Fariel Shafee, and William Bialek. 2002. Entropy and inference, revisited. In Advances in Neural Information Processing Systems 14, pages 471-478. MIT Press.
Parker, James. 1894. A glossary of terms used in heraldry.
http://www.heraldsnet.org/saitou/parker/gallery/Page.html.
Parpola,
Asko. 1994. Deciphering the
Parpola,
Asko. 2005. Study of the
Parpola,
Asko. 2008. Is the
http://www.harappa.com/script/indus-writing.pdf.
Pereira, Fernando. 2009. Falling for the magic formula.
http://earningmyturns.blogspot.com/2009/04/falling-for-magic-formula.html.
Possehl,
Gregory. 1996. The
Possehl, Gregory. 2004. Quoted in (Lawler 2004), page 2028.
Rao,
Rajesh. 2010a. Block entropy analysis of the
http://www.cs.washington.edu/homes/rao/BlockEntropy.html.
Rao, Rajesh. 2010b. Probabilistic analysis of an ancient undeciphered script. IEEE Computer, 43(4):76-80.
Rao,
Rajesh, Nisha Yadav, Mayank Vahia, Hrishikesh
Joglekar, R. Adhikari,
and Iravatham Mahadevan.
2009a. Entropic evidence for linguistic structure in the
Rao,
Rajesh, Nisha Yadav, Mayank Vahia, Hrishikesh
Joglekar, R. Adhikari,
and Iravatham Mahadevan.
2009b. A Markov model of the
Schmitt, Armin and Hanspeter Herzel. 1997. Estimating the entropy of
DNA sequences. J. Theor. Biol., 1888:369-377.
Seidl, Ursula. 1989. Die babylonischen Kudurru-Reliefs. Symbole
mesopotamischer Gottheiten. Universitätsverlag Freiburg, Freiburg.
Shannon, Claude. 1948. A mathematical theory of communication. Bell System Technical Journal, 27:379-423, 623-656.
Shannon, Claude. 1951. Prediction and entropy of printed English. Bell System Technical Journal, 30:50-64.
Siddharthan,
Rahul. 2009. More
http://horadecubitus.blogspot.com/2009/05/more-indus-thoughts-and-links.html.
Slanski,
Kathryn. 2003. The Babylonian entitlement narûs
(kudurrus): a study in their form and function.
American Schools of Oriental Research,
[ Snyder, Barzilay, and Knight2010]
Snyder, Benjamin,
Sproat, Richard. 2010. Ancient symbols, computational linguistics, and the reviewing practices of the general science journals. Computational Linguistics, 36(3).
Vidale, Massimo. 2007. The collapse melts down: a reply to Farmer, Sproat and Witzel. East and West, 57:333-366.
Winn, Shan. 1990. A Neolithic
sign system in southeastern
Yadav, Nisha, Hrishikesh Joglekar, Rajesh Rao, Mayank Vahia, Ronojoy
Adhikari, and Iravatham Mahadevan. 2010. Statistical analysis of the
Yadav, Nisha, Mayank Vahia, Iravatham Mahadevan, and Hrishikesh Joglekar. 2008a. Segmentation of Indus texts. International Journal of Dravidian Linguistics, 37(1):53-72.
Yadav, Nisha, Mayank Vahia,
Iravatham Mahadevan, and Hrishikesh Joglekar. 2008b. A
statistical approach for pattern search in
Footnotes:
1Affiliations: R. P.
N. Rao: Dept. of Comp. Sci. &
2Under certain assumptions, one can derive a quantitative estimate of the increase in posterior probability from a result such as Figure 1(b). We refer the reader to [ Siddharthan2009] for details.