Myria Middleware for Polystores
RACO (the Relational Algebra COmpiler) is a polystore middleware system that provides query translation, optimization, and orchestration across complex multi-system big data ecosystems. RACO provides language and optimization services for the Myria big data management stack and serves as a core component of that project. In addition to Myria, RACO includes support for Spark, SciDB, Grappa, C, and SQL backends.
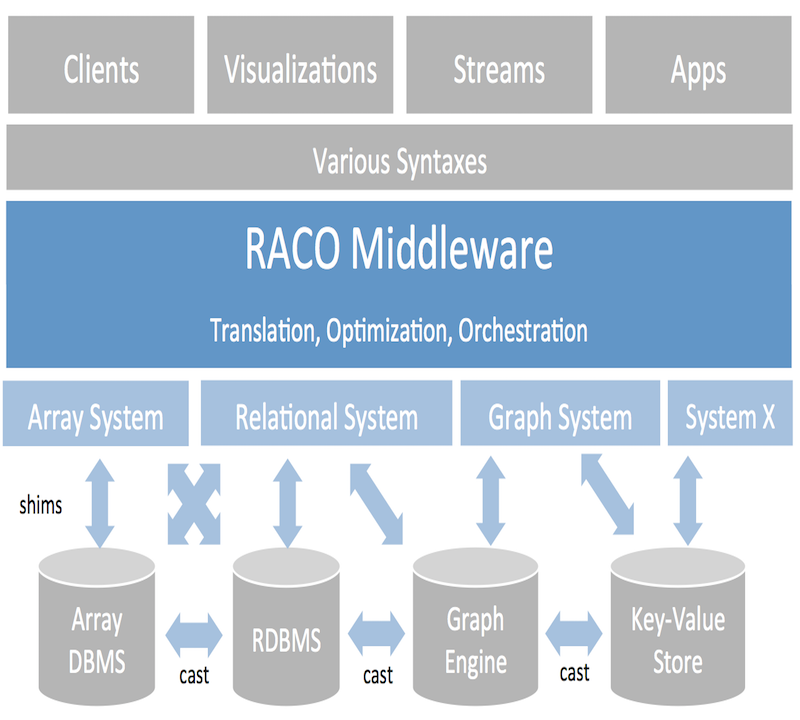
Why does RACO exist?
There has been a "Cambrian explosion" of big data systems proposed and evaluated in the last eight years, but relatively little understanding of how these systems or the ideas they represent compare and complement one another. In both enterprise and science situations, "one size does not fit all": we see analytics teams running multiple systems simultaneously, including specialized systems for limited use cases.
The proliferation of systems has lead to a surfeit of languages and APIs. It is time to consider a new framework that can span these systems and simplify the programming and maintenance of Big Data applications. There are two key goals for such a framework:
-
Portability: It should be relatively easy to move an application or tool developed on one platform to op- erate against another. As a corollary, back-end data and analytics services should be swappable. At best, interoperability between current systems amounts to reading and writing files via HDFS or running ETL procedures, then switching to a new programming en- vironment. However, we see relatively few data mod- els (relations, arrays, graphs, key-value pairs) and relatively few computational models (relational algebra, parallel data-flow, iteration, linear algebra), suggesting that the heterogeneity we see in practice may amount to implementation details rather than fundamental in- compatibilities.
-
Multi-Server Applications: It will be more common than not that a particular application will need to in- voke the services of multiple systems. The framework should make is easy to construct such applications, optimize and manage their execution, and keep track of the results in a shared catalog.
We are designing RACO to fullfill these requirements. More generally, we are interested in measuring the price of abstraction: Can we generate code that competes with hand-authored programs, including programs in HPC contexts? Our hypothesis is that we can: there seem to be similarities between the ``tricks’’ used in enterprise big data systems and scientific programming contexts related to handling skew, dynamic partitioning, and managing iteration. We aim to model and exploit these tricks to provide a common programming model without paying performance penalties.
Current Team
- Dylan Hutchison
- Dominik Moritz
- Shrainik Jain
Alumni
- Brandon Myers (now at University of Iowa)
- Seung-Hee Bae (now at University of Western Michigan)
- Jeremy Hyrkas (now at Microsoft)
- Marianne Shaw (now at Tableau)
- Dan Halperin (now at Google)
- Andrew Whitaker (now at Amazon)
Software
Papers
- SQLShare: Results from a Multi-Year SQL-as-a-Service Experiment
Shrainik Jain, Dominik Moritz, Bill Howe, Ed Lazowska.
SIGMOD 2016 - High Variety Cloud Databases
Shrainik Jain, Dominik Moritz, Bill Howe.
Workshop on Cloud Data Management (CloudDM) (co-located with ICDE) [invited keynote] 2016@inproceedings{jain2015highvariety, author = {Jain, Shrainik and Moritz, Dominik and Howe, Bill}, title = {High Variety Cloud Databases}, booktitle = {Workshop on Cloud Data Management (CloudDM) (co-located with ICDE) [invited keynote]}, year = {2016} } - A Demonstration of the BigDAWG Polystore System
Aaron Elmore, Jennie Duggan, Michael Stonebraker, Magdalena Balazinska, Ugur Cetintemel, Vijay Gadepally, Jeffrey Heer, Bill Howe, Jeremy Kepner, Jeremy Kraska, Jeremy Madden, Jeremy Maier, Jeremy Mattson, Tim Papadopoulos.
Proc. Very Large Database Endowment (PVLDB) 8(12) 2015@article{elmore2015demo, title = {A Demonstration of the BigDAWG Polystore System}, author = {Elmore, Aaron and Duggan, Jennie and Stonebraker, Michael and Balazinska, Magdalena and Cetintemel, Ugur and Gadepally, Vijay and Heer, Jeffrey and Howe, Bill and Kepner, Jeremy and Kraska, Tim and Madden, Samuel and Maier, David and Mattson, Timothy and Papadopoulos, Stavros and Parkhurst, Jeff and Tatbul, Nesime and Vartak, Manasi and Zdonik, Stan}, journal = {Proc. Very Large Database Endowment (PVLDB)}, year = {2015}, volume = {8}, number = {12}, url = {http://idl.cs.washington.edu/papers/bigdawg-demo} } - The BigDAWG Polystore System
Jennie Duggan, Aaron J. Elmore, Michael Stonebraker, Magdalena Balazinska, Bill Howe, Jeremy Kepner, Sam Madden, David Maier, Tim Mattson, Tim Zdonik.
SIGMOD Record 44(2) 2015@article{duggan2015polystore, author = {Duggan, Jennie and Elmore, Aaron J. and Stonebraker, Michael and Balazinska, Magdalena and Howe, Bill and Kepner, Jeremy and Madden, Sam and Maier, David and Mattson, Tim and Zdonik, Stanley B.}, title = {The BigDAWG Polystore System}, journal = {SIGMOD Record}, volume = {44}, number = {2}, pages = {11--16}, year = {2015}, url = {http://doi.acm.org/10.1145/2814710.2814713}, doi = {10.1145/2814710.2814713}, timestamp = {Thu, 13 Aug 2015 11:37:00 +0200}, biburl = {http://dblp.uni-trier.de/rec/bib/journals/sigmod/DugganESBHKMMMZ15}, bibsource = {dblp computer science bibliography, http://dblp.org} } - Demonstration of the Myria big data management service
Daniel Halperin, Victor Almeida, Lee Lee Choo, Shumo Chu, Paraschos Koutris, Dominik Moritz, Jennifer Ortiz, Vaspol Ruamviboonsuk, Jingjing Wang, Jingjing Whitaker, Jingjing others.
Proceedings of the 2014 ACM SIGMOD international conference on Management of data 2014@inproceedings{halperin2014demonstration, title = {Demonstration of the Myria big data management service}, author = {Halperin, Daniel and Teixeira de Almeida, Victor and Choo, Lee Lee and Chu, Shumo and Koutris, Paraschos and Moritz, Dominik and Ortiz, Jennifer and Ruamviboonsuk, Vaspol and Wang, Jingjing and Whitaker, Andrew and others}, booktitle = {Proceedings of the 2014 ACM SIGMOD international conference on Management of data}, pages = {881--884}, year = {2014}, organization = {ACM} } - Compiled Plans for In-Memory Path-Counting Queries
Brandon Myers, Jeremy Hyrkas, Daniel Halperin, Bill Howe.
Proceedings of the 1st International Workshop on In Memory Data Management and Analytics, IMDM 2013, Riva Del Garda, Italy, August 26, 2013. 2013@inproceedings{myers2013compiled, author = {Myers, Brandon and Hyrkas, Jeremy and Halperin, Daniel and Howe, Bill}, title = {Compiled Plans for In-Memory Path-Counting Queries}, booktitle = {Proceedings of the 1st International Workshop on In Memory Data Management and Analytics, {IMDM} 2013, Riva Del Garda, Italy, August 26, 2013.}, pages = {25--37}, year = {2013}, crossref = {DBLP:conf/vldb/2013imdm}, url = {http://www-db.in.tum.de/other/imdm2013/papers/Myers.pdf}, timestamp = {Wed, 17 Sep 2014 19:55:20 +0200}, biburl = {http://dblp.uni-trier.de/rec/bib/conf/vldb/MyersHHH13}, bibsource = {dblp computer science bibliography, http://dblp.org} }
projects
This webpage was built with Bootstrap and Jekyll. You can find the source code here. Last updated: Aug 02, 2021