Semantic World Models
Jacob Berg, Chuning Zhu, Yanda Bao, Ishan Durugkar, Abhishek Gupta
website
/ paper

Jacob Berg, Chuning Zhu, Yanda Bao, Ishan Durugkar, Abhishek Gupta
website
/ paper
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, Abhishek Gupta
Robotics: Science and Systems (RSS), 2025
ICML Workshop on Building Physically Plausible World Models, 2025
(best paper award)
website
/ paper
/ code
/ talk

Chuning Zhu, Xinqi Wang, Tyler Han, Simon Shaolei Du, Abhishek Gupta
Neural Information Processing Systems (NeurIPS), 2024
ICML Workshop on Structured Probabilistic Inference & Generative Modeling, 2024
website
/ paper
/ code

Marius Memmel, Andrew Wagenmaker, Chuning Zhu, Patrick Yin, Dieter Fox, Abhishek Gupta
International Conference on Learning Representations (ICLR), 2024
(oral, top 1%)
website
/ paper
/ code
/ talk

Zhaoyi Zhou, Chuning Zhu, Runlong Zhou, Qiwen Cui, Abhishek Gupta, Simon Shaolei Du
International Conference on Learning Representations (ICLR), 2024
NeurIPS Workshop on Foundation Models for Decision Making (FMDM), 2023
(oral, 6/112)
website
/ paper
/ code
/ talk
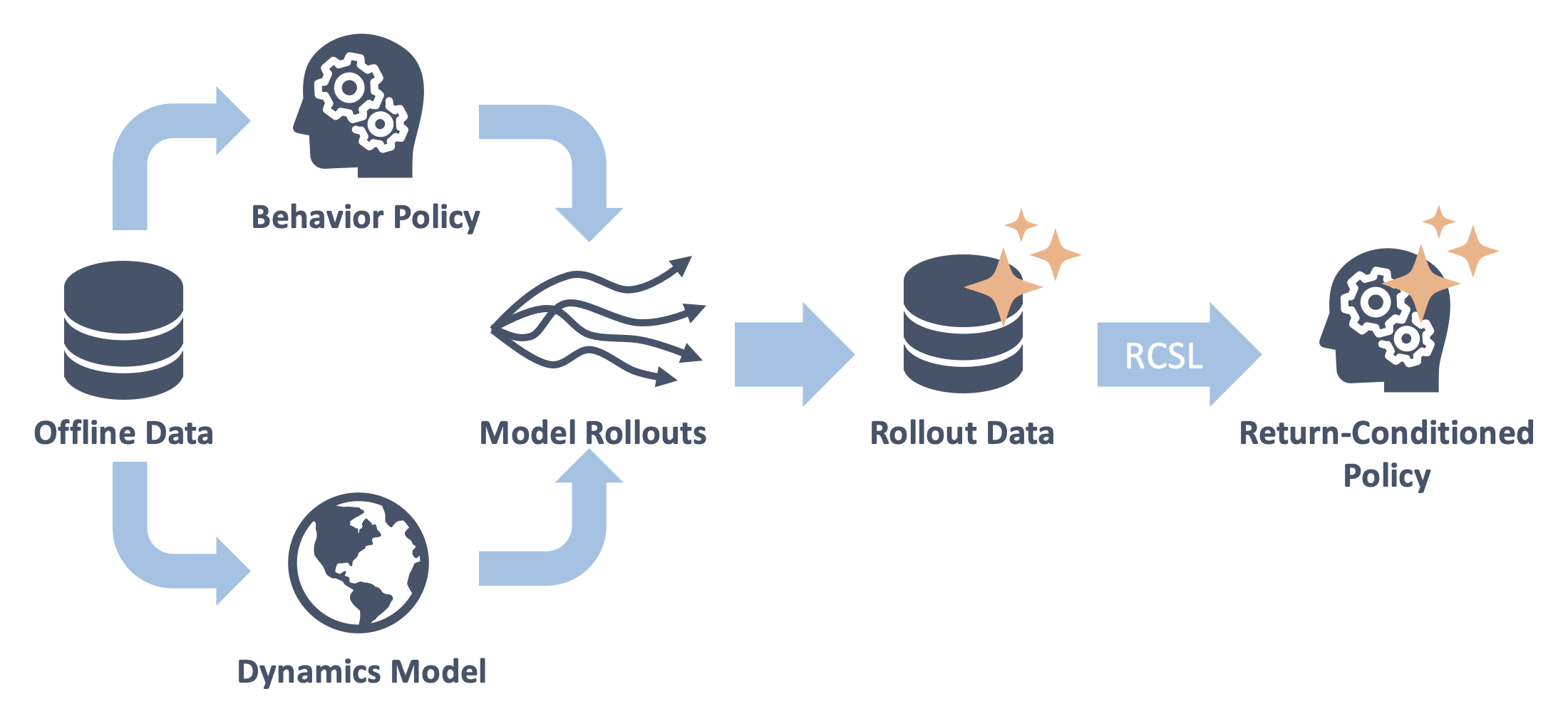
Chuning Zhu, Max Simchowitz, Siri Gadipudi, Abhishek Gupta
Neural Information Processing Systems (NeurIPS), 2023
(spotlight)
website
/ paper
/ code
/ talk
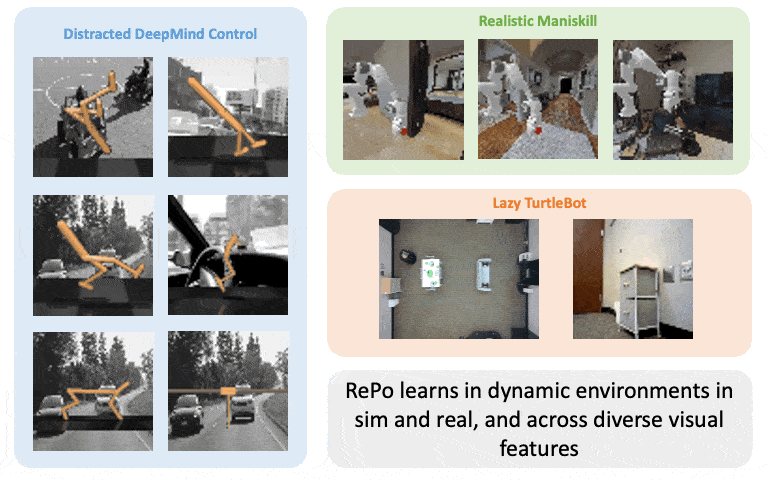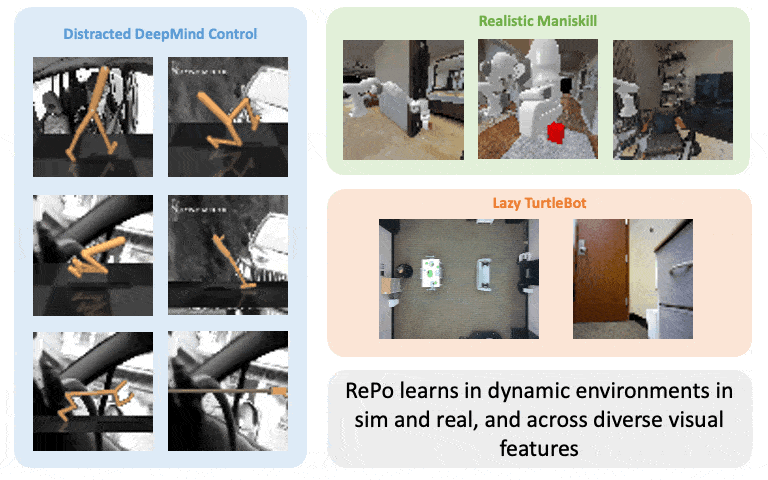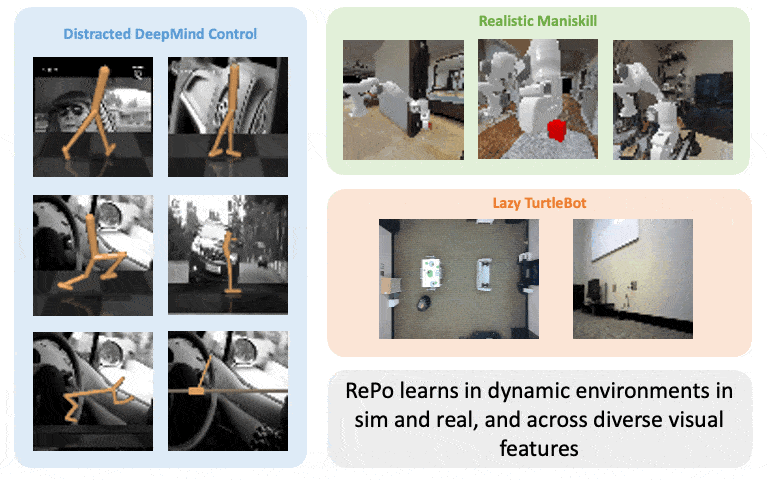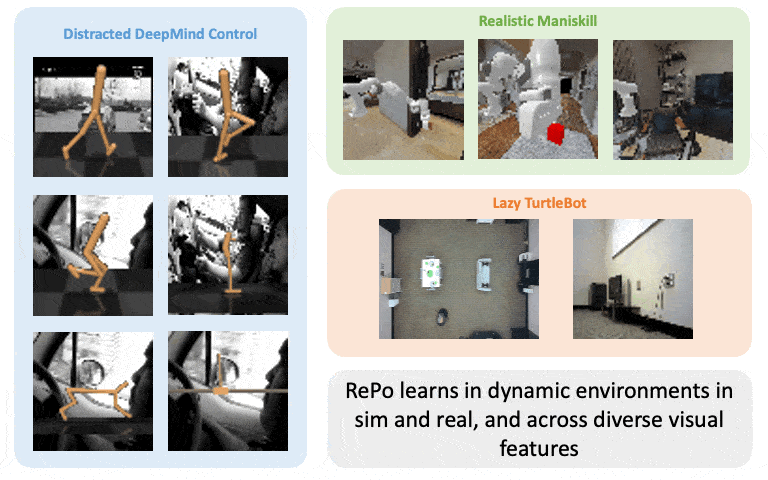
Boyuan Chen*, Chuning Zhu*, Pulkit Agrawal, Kaiqing Zhang, Abhishek Gupta
Neural Information Processing Systems (NeurIPS), 2023
website
/ paper
/ code
/ talk
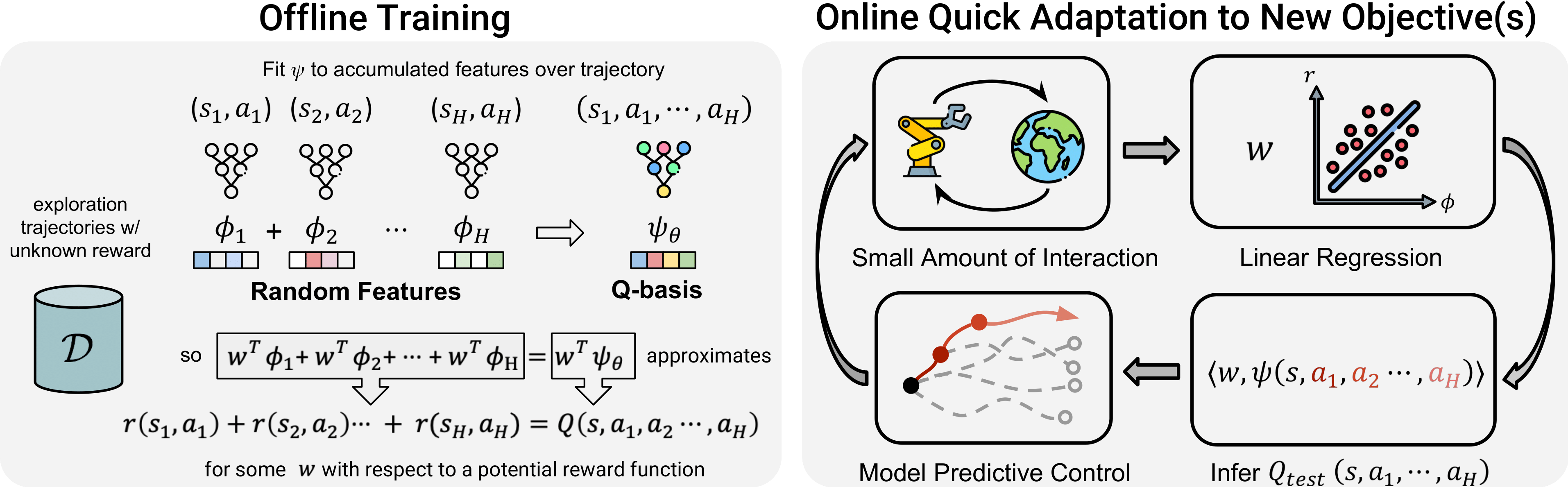
Oleh Rybkin*, Chuning Zhu*, Anusha Nagabandi, Kostas Daniilidis, Igor Mordatch, Sergey Levine
International Conference on Machine Learning (ICML), 2021
website
/ paper
/ code
/ talk
