Constraint Learning for Control Tasks
with Limited Duration Barrier Functions
Because control policies that keep a dynamical agent within state constraints over infinite horizons are not always available, we consider constraints that can be satisfied over some finite time horizon T > 0 (limited-duration safety).

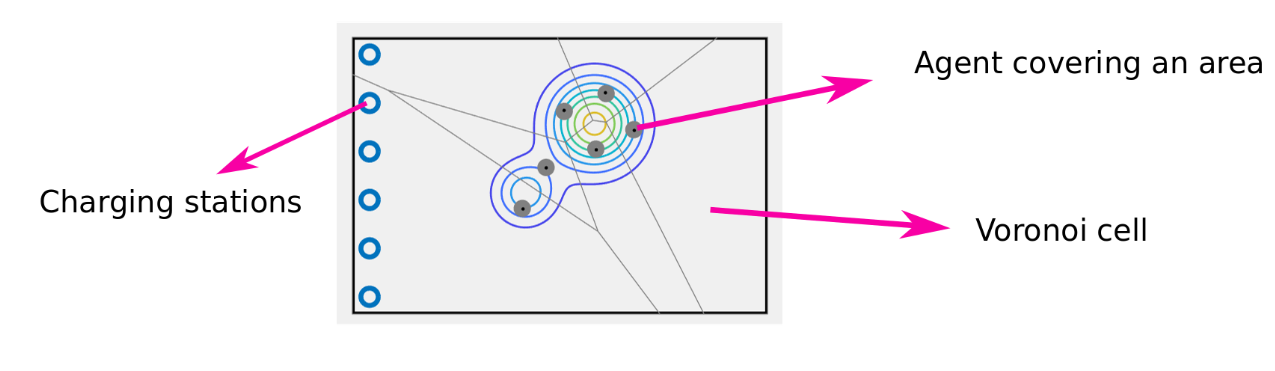
Actually, the existence of limited-duration safe policies is sufficient for long-duration autonomy in some application. This idea was illustrated on a swarm of robots that are tasked with covering a given area, but that sporadically need to abandon this task to charge batteries.
A benefit of considering limited-duration safety is that one can use value function learning to find limited-duration safe policies.
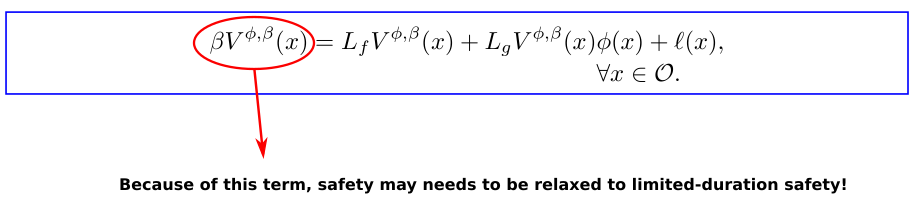
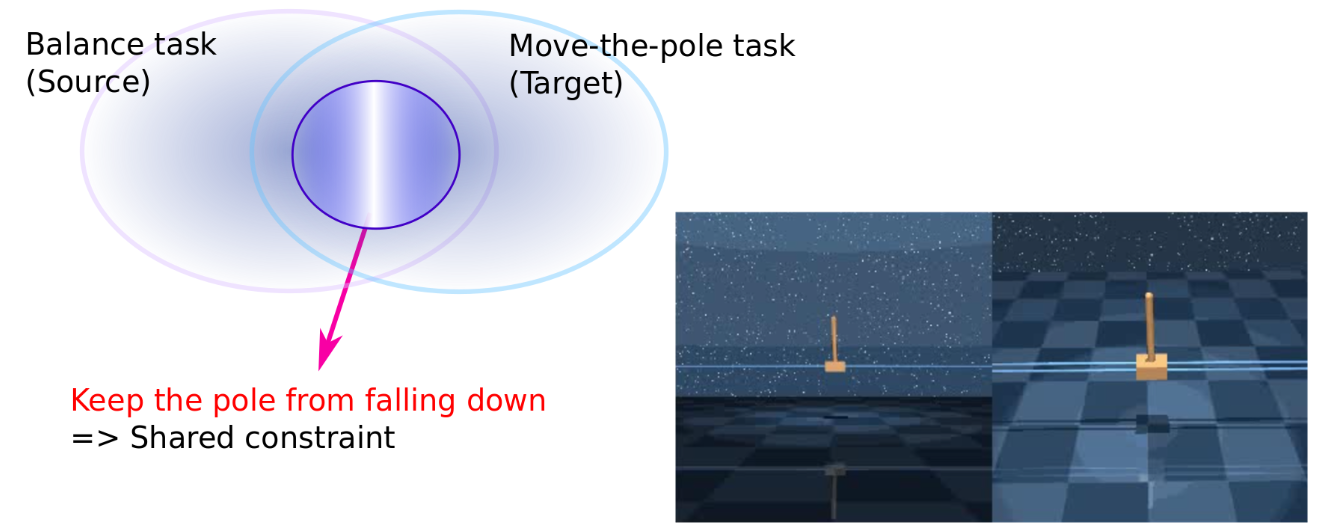
Also, when different tasks share same safety constraints, one can transfer a set of limited-duration safe policies (or good-enough policies) from one task to another.