Mark H. Oskin
Professor at the Paul G. Allen School of Computer Science & Engineering, University of Washington. Computer architecture, parallel systems, and the occasional foray into the implausible.

Professor at the Paul G. Allen School of Computer Science & Engineering, University of Washington. Computer architecture, parallel systems, and the occasional foray into the implausible.
I write a lot of code with AI these days. Here are some examples you might enjoy actually using.
My recent machine learning work is on interpretability. The dominant approach to understanding what a language model "knows" is to reverse‑engineer a trained network after the fact. I have been asking a different question: what if we build the model so its internals are readable from the start? The idea is to rebuild the transformer out of explicit fuzzy set operations — intersection A·B, set‑difference A·(1−B) — over sigmoid‑bounded [0,1] memberships, so that individual hidden units function as named logical operators rather than opaque activations.
The first paper does this for the feed‑forward layer, adding a negation‑capable FFN and a self‑forgetting sequence quantifier; the units read out as grammatical‑licensing detectors that identify licensors like comparatives and negative‑polarity items. The second carries the same idea into attention and joins the two into a single end‑to‑end legible model. The load‑bearing decision turns out to be bounding what a head detects while leaving what it writes unconstrained. Across five specialized‑attention designs at 125M parameters, 44–62% of value channels become crisp, contextually selective detectors — and language‑model quality stays at parity with a conventional baseline.
The third paper is the capstone of the series: it works out how to actually train, read, and edit these models — including a fix for a training pathology where the obvious "crispness" penalty collapses operators into dead constants. The result is a model in which 78% of feed‑forward operands and 50% of attention value channels read as crisp, contextual detectors, with a "legibility dial" that trades circuit reuse for independence and localized edits that are 50–184× more contained in the deep layers, all still at parity with a conventional baseline.
It has been a few years (decades?) since architects looked seriously at FGMT architectures. In that time much has changed on both the technology and application fronts. We have built a modern FGMT core, integrated into a manycore fabric, and are currently adding new features to it. Stay tuned…
Active development. Publications forthcoming.
This project aims to design a safer RTL language to engineer out some of the modern bugs we see in hardware systems. Our goal is to make hardware secure by construction.
Active development. Publications forthcoming.
This project's goal is to write an entire operating system using LLM code generation.
Project page and preliminary tools: Vibe tools.
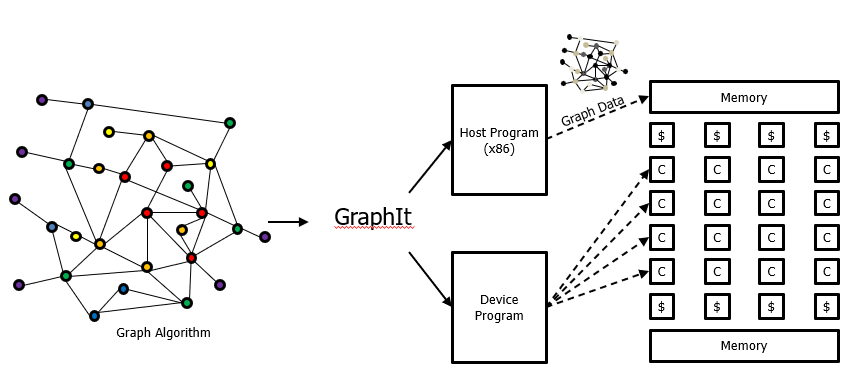
My interest in computing on large‑scale graphs continued from the PGAS + Grappa work below. Here we built a custom manycore device aiming to be a "jack of all trades," best‑in‑class compute fabric for many applications. A big collaboration with Michael Taylor, Luis Ceze, Adrian Sampson, Chris Batten and Zhiru Zhang. We call this chip HammerBlade: the project is funded by DARPA and we thought naming it after the famous swords‑to‑ploughshares statue was funny.
HammerBlade is quite different from prior PGAS work. It is a tiled array of simple in‑order cores. Each core has a small (4K) local data store. Cores can directly read and write each other's memory and have access to die‑stacked HBM. There are no data caches at the cores themselves, although caches are used at the HBM interface to increase effective bandwidth and provide efficient fine‑grained access.
To support graph computations on HammerBlade we ported the GraphIt compiler from MIT. We were able to adapt both the compiler and the hardware — for example, we found it useful to have non‑blocking loads on the in‑order cores for efficient block transfers from HBM to local data store. On the software front we implemented a form of tiling for graph execution that more efficiently utilizes HBM bandwidth.
Michael Taylor, Ajay Joshi and I started an effort to build a best‑in‑class in‑order RISC‑V multicore. The design goals were ambitious: open source with intentional community building; written in industry‑standard SystemVerilog; designed to commercial‑quality levels of design review and MAS documentation; silicon‑validated at 12nm and able to boot Linux; and fast in absolute performance and in area/power/performance metrics.
We named this processor BlackParrot and pulled together an extremely talented team of students. Silicon came back in spring and was working within 30 minutes.
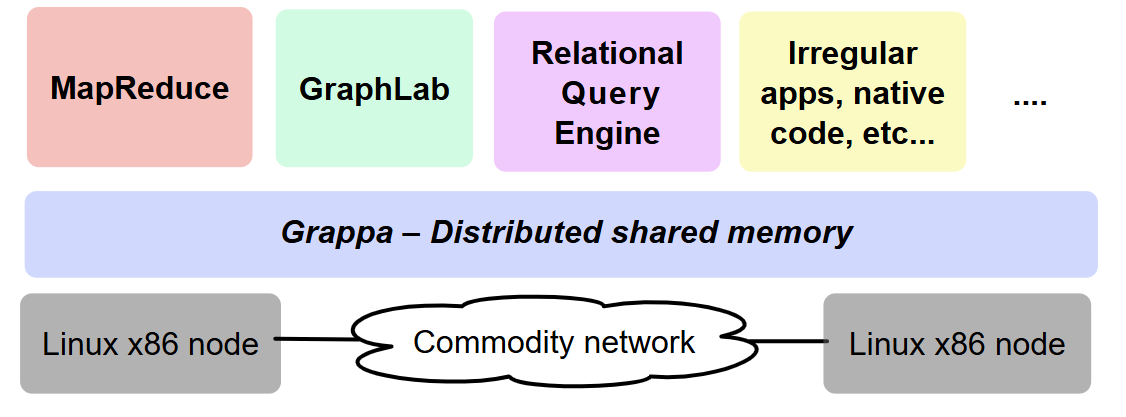
When I returned from Corensic I started work on a runtime system for clusters that would make graph execution efficient. This became Grappa, a partitioned global address space (PGAS) runtime. Grappa was inspired by the Tera MTA and ideas from Burton Smith, whom I dearly miss. To tolerate remote memory latency, computation on the CPU is overlapped with work from other threads. Unlike the MTA — which needed ~128 threads per CPU to tolerate main‑memory latency — Grappa needs ~5,000 threads per CPU to tolerate inter‑machine latency.
Grappa has other tricks: it uses message aggregation to trade network latency for bandwidth, and supports in‑memory computation delegates that speed up synchronization. It also (optionally) had a really cool compiler that directly supported global memory pointers and could transform threads into continuations automatically.
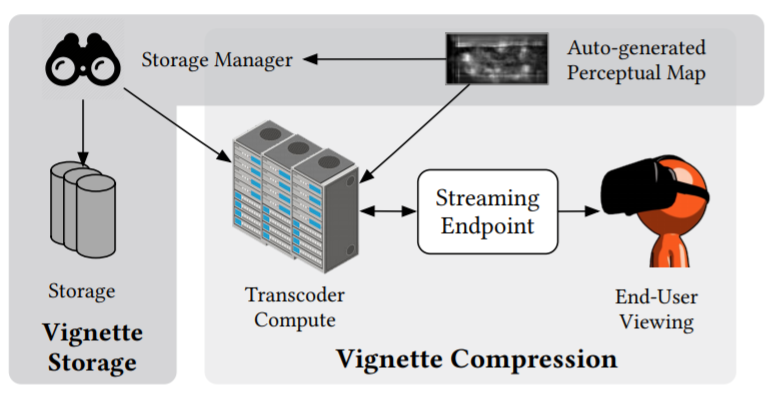
In 2016, Amrita Mazumdar and Vincent Lee joined my research group, interested in the intersection of video, machine learning and computer architecture. With Luis Ceze, we explored how to efficiently recognize faces and individuals in IoT camera systems by partitioning effort between a small low‑power face detection circuit on the device and full recognition on the server. To accelerate recognition, we examined similarity search in a processor‑in‑memory (PIM) device. We also looked at hardware support for immersive 3D video — performing bilateral solving in real time.
The conclusion of this line of work is what I am most excited about: by understanding the limitations of the human eye we can use a neural network to predict where in a video viewers will look and then re‑encode with non‑uniform within‑frame quality. Viewers report better‑looking videos than conventional compression, and decoding requires less energy — hardware experiments on real phones demonstrate a 67% improvement in battery life.
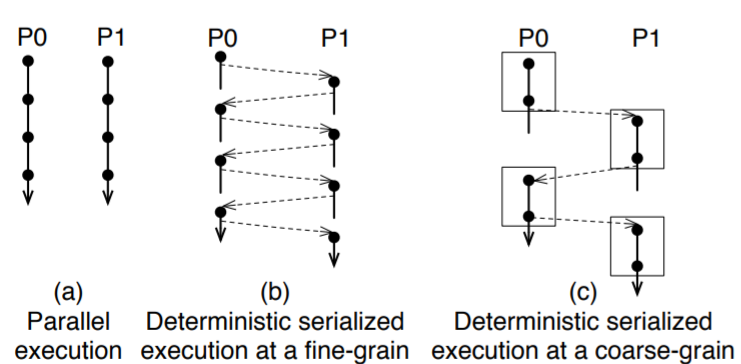
Soon after Luis Ceze arrived at UW he came to my office and said writing multiprocessor code would be a lot easier if multiprocessors were deterministic. I quipped back: well, that's easy — just remove the parallelism and make them sequential. A couple of days later I sketched out a primitive form of the "sharing table" on Luis's whiteboard — a technique that allowed parallelism while maintaining sequential semantics. We later realized Lamport's vector clocks could formalize this, and that speculation could regain more parallelism.
Luis built a fantastic research program on the idea, and the students from that group have had profound impact on academia and industry. I took the idea and founded a startup, Corensic, which built a hypervisor that could on‑demand turn a guest operating system into deterministic mode and run carefully controlled parallel snapshots to find or avoid multithreaded bugs. An amazing technological achievement — but a failed product. I learned that while people say they care about software quality, no one from developers to managers to end users is willing to pay for it. The world also changed under our feet: the App Store happened. We live in the age of the $2 app.
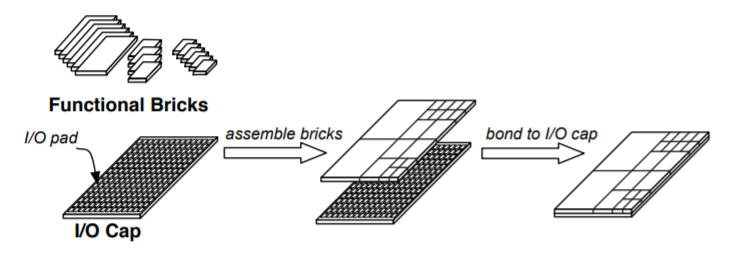
This project started with a simple question Todd Austin asked me one day as we walked across Red Square at UW: "how do we make chip manufacturing so cheap you can do it at home?" The key, I realized, was the modern‑day equivalent of the 74xx series of TTL DIP parts: components — CPUs, PCIe controllers, accelerators — that people would order from the likes of Digi‑Key, plus a backplane chip with an on‑chip network to interconnect anything. These would be bonded together "at home." And just in case that wasn't crazy enough for 2006/7, we threw in something extra: precise‑shaped "bricks" supporting automated self‑assembly.
The self‑assembly part never came to pass, but the idea of assembling chips from bricks did. We call them chiplets today, and large commercial parts are assembled with both passive and active interposers.
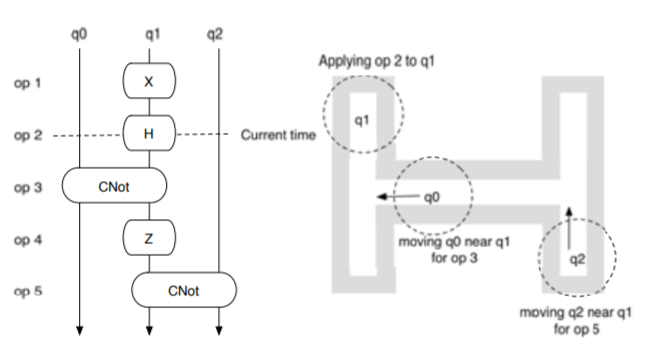
I started work on architectural support for quantum computers as a graduate student working with Fred Chong, who was good friends with Isaac Chuang — who had just finished building a bulk‑spin quantum computer at IBM and taken a job at MIT. After graduating, I continued the work as an Assistant Professor at UW. The architecture community had a wide range of opinions on quantum computing at the time, from calling it "mediocre science fiction, at best" (an actual review I received) to game‑changing. We took the science‑fiction review with good cheer — it became the motto for our research group. Somewhere I still have our team T‑shirt with it printed on it.
Things have come a long way. We now have commercially available quantum computers, and "quantum supremacy" has been achieved. Quantum architecture is now an accepted subdiscipline within computer architecture. I still work in a space adjacent to quantum computing, but not at UW.
WaveScalar began as an effort to chase all the instruction‑level parallelism one could ever have. Inspired by Monica Lam's pioneering paper on the limits of control flow on ILP, we focused on unlocking parallelism in imperative language programs (e.g. C) by breaking those control‑flow limits. Along the way, we realized we were building a dataflow machine — but unlike any built before. It had a conventional memory system and hardware support to make dataflow execution of imperative software fast and correct.
The project was extremely exciting, and I learned something about ILP that has stuck with me: there are two points of sequentialization in a superscalar processor — instruction fetch and memory reads/writes. WaveScalar parallelized instruction fetch to the absolute limit, but the memory interface was only parallelized to the limit of what a compiler could express statically. This ultimately constrained performance. The challenge remains for another day: unlock the parallelism at the memory side.