
|
|
|
 |
Mark Oskin
|
| Current | Alumni | Sage advice for students |
|
|
|
Graphs Execution on Manycores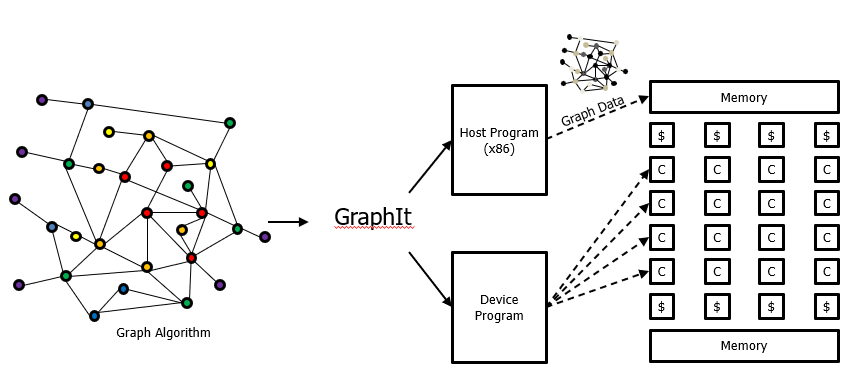
My interest in computing on large scale graphs remains (see PGAS + Grappa below). Currently we are building a custom manycore device that is trying to be a "jack of all trades", best in class compute frabric for all sorts of applications. This is a big effort with many collaborators including Michael Taylor, Luis Ceze, Adrian Sampson, Chris Batten and Zhiru Zhang. We call this chip HammerBlade because the project is funded by DARPA and we thought it would be funny to name the project after the famous swords to ploughshares statue. HammerBlade is quite different than my prior PGAS work. It is a tiled array of simple in order cores. Each core has a small (4K) local data store. Cores can directly read and write each other's memory and have access to die stacked HBM memory. There are no data caches at the cores themselves, although caches are used at the HBM interface in order to increase effective bandwidth and provide efficient fine-grained access. Work is ongoing on the both the hardware and software designs. To support graph computations on HammerBlade we have ported the GraphIt compiler originally developed at MIT. GraphIt provides an easy to use language to express graph computations. Unlike Grappa we have the opportunity to adapt both the compiler and the hardware. For example, we found it useful to have non-blocking loads on the in-order cores of the HammerBlade device. These are used by our GraphIt backend for efficient block transfers of data from HBM to the core's local data-store. On the software front we have implemented a form of tiling for graph execution that more efficiently utilizes HBM bandwidth. |
We are still working on the seminal paper (and we do have a lot to say). For now you can read more about the effort here |
Open Source Hardware
Michael Taylor, Ajay Joshi and I started an effort to build a best-in-class in-order RISC-V multicore. There were many design goals: It is open source with intentional community building efforts. It was to be written in industry standard System Verilog. It was to be designed to commercial-quality levels of design review and microarchitectural specification (MAS) documentation. It was to be silicon validated at 12nm and boot Linux. Finally, it was to be fast in both absolute performance and in area, power, performance metrics. We named this processor BlackParrot and an extremely talented team of students was pulled together to construct it. Silicon came back this Spring and was working within 30 minutes. |
Daniel Petrisko, Farzam Gilani, Mark Wyse, Tommy Jung, Scott Davidson, Paul Gao, Chun Zhao, Zahra Azad, Sadullah Canakci, Bandhav Veluri, Tavio Guarino, Ajay Joshi, Mark Oskin, Michael Taylor, BlackParrot: An Agile Open Source RISC-V Multicore for Accelerator SoCs, IEEE Micro 2020, 10.1109/MM.2020.2996145 Project homepage here |
PGAS For Graphs
When I returned from Corensic I started work on developing a runtime system for a cluster of machines that would make graph execution efficient. This runtime system eventually became Grappa, a partitioned global address space (PGAS) runtime. Grappa was inspired by the Tera MTA and ideas from Burton Smith, whom I dearly miss. To tolerate remote memory latency computation on the CPU was overlapped with work from other threads. Unlike the MTA, which needed ~ 128 threads per CPU to tolerate main memory latency, Grappa needs about 5,000 threads per CPU to tolerate inter-machine latency. Grappa has other tricks up its sleeve too. For example, it uses a technique of message aggregation to trade-off network latency for bandwidth. It also supports a form of ``in-memory'' computation delegates which speeds up synchronization. Grappa also (optionally) had a really cool compiler which directly supported global (whole system) memory pointers and that could transform programmer threads into continuations automatically. These last two features I think are particularly useful and I'll be using them in my latest ``big graph'' work (see above). |
Brandon Holt, Jacob Nelson, Brandon Myers, Preston Briggs, Luis Ceze and Mark Oskin, Flat Combining Synchronized Global Data Structures, International Conference on PGAS Programming Models, October 2013 Brandon Holt, Preston Briggs, Luis Ceze, Mark Oskin. Alembic: Automatical Locality Extraction via Migration, OOOPSLA, October 2014 Jacob Nelson, Brandon Holt, Brandon Myers, Preston Briggs, Luis Ceze, Simon Kahan, Mark Oskin. Lateny-Tolerant Software Distributed Shared Memory, USENIX ATC, July 2015 Best paper award Brandon Holt, James Bornholt, Irene Zhang, Dan Ports, Mark Oskin and Luis Ceze, Disciplined Inconsistency with Consistency Types, ACM Symposium on Cloud Computing (SoCC), Oct 2016. Project link. |
Architectures for Visual Systems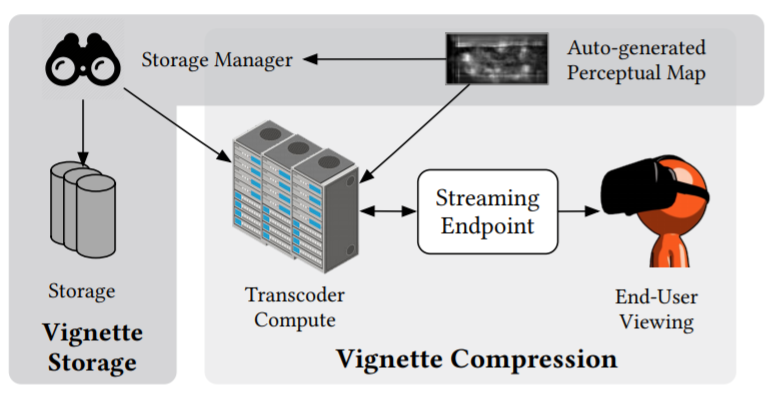 In 2016 a pair of students, Amrita Mazumdar and Vincent Lee joined my research group. They were generally interested in the intersection of video, machine-learning and computer architecture. Collaborated with Professor Luis Ceze we initially explored how to efficiently recognize faces and individuals in IoT camera systems. The key idea behind this work is to partition the effort between a small low power face detection circuit in the IoT device itself and perform actual recognition at the server side. To accelerate the recognition process, we looked at performing similarity search in a processor-in-memory (PIM) device. We also looked at hardware support for immersive 3D video. This hardware performs bilateral solving in real-time. The conclusion of this work is what I am most excited about. By understanding the limitations of the human eye we can use a neural network to predict where in a video viewers will look and then re-encode the video in non-uniform within a frame quality. Not only do viewers report that the videos look better than conventional compression, they require less energy at the viewing device to decode. Hardware experiments on real phones demonstrate a 67% improvement in battery life.
In 2016 a pair of students, Amrita Mazumdar and Vincent Lee joined my research group. They were generally interested in the intersection of video, machine-learning and computer architecture. Collaborated with Professor Luis Ceze we initially explored how to efficiently recognize faces and individuals in IoT camera systems. The key idea behind this work is to partition the effort between a small low power face detection circuit in the IoT device itself and perform actual recognition at the server side. To accelerate the recognition process, we looked at performing similarity search in a processor-in-memory (PIM) device. We also looked at hardware support for immersive 3D video. This hardware performs bilateral solving in real-time. The conclusion of this work is what I am most excited about. By understanding the limitations of the human eye we can use a neural network to predict where in a video viewers will look and then re-encode the video in non-uniform within a frame quality. Not only do viewers report that the videos look better than conventional compression, they require less energy at the viewing device to decode. Hardware experiments on real phones demonstrate a 67% improvement in battery life.
Amrita is finishing her Ph.D. and has founded a startup to commercialize the pereceptual compression work. That idea has the chance to have significant impact on everyday users. |
Amrita Mazumdar, Armin Alaghi, Thierry Moreau, Sung Min Kim, Meghan Cowan, Luis Ceze, Mark Oskin, Visvesh Sathe. Exploring Computation-Communication Tradeoffs in Camera Systems, IEEE International Symposium on Workload Characterization 2017. Amrita Mazumdar, Armin Alaghi, Jonathan T. Barron, David Gallup, Luis Ceze, Mark Oskin, Steven M. Seitz. A Hardware-Friendly Bilateral Solver for Real-Time Virtual Reality Video, High Performance Graphics 2017. Vincent T. Lee, Amrita Mazumdar, Carlo C. del Mundo, Armin Alaghi, Luis Ceze, Mark Oskin. Application Codesign of Near-Data Processing for Similarity Search, International Parallel and Distributed Processing Symposium (IPDPS) 2018. A. Mazumdar, B. Haybers, M. Balazinska, L. Ceze, A. Cheung, M. Oskin, Perceptual Compression of Video Storage and Processing Systems, Proceedings of the ACM Symposium on Cloud Computing, ACM, 2019. |
Deterministic Multiprocessing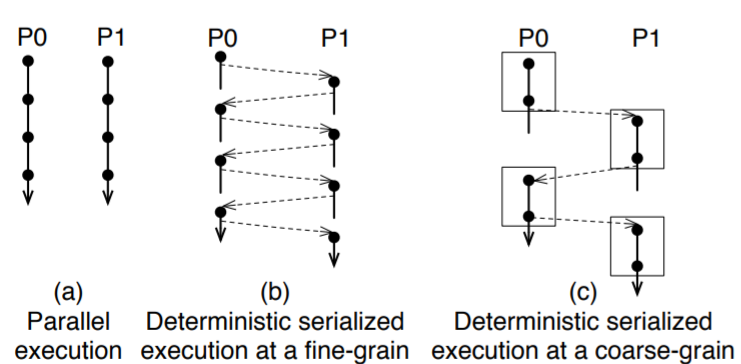
Soon after Luis Ceze arrived at UW he came to my office and said writing multiprocessor code would be a lot easier if multiprocessors were deterministic. I quipped back, well that is easy, just remove the parallelism and make them sequential. A couple of days later I sketched out a primitive form of the ``sharing table'' on Luis's whiteboard, a technique that would allow for parallelism yet maintain sequential semantics. Ultimately we realized Lamport's vector clocks could formalize this approach. We also derived that speculation could be used to regain even more parallelism. Luis went on and built a fantastic research program on the idea. The students that have came from that group have had profound impact on academia and industry. I took the idea and founded a startup company, Corensic. Corensic assembled a fantastic collection of systems engineers where we built a hypervisor that could on-demand turn a guest operating system into deterministic mode. More than just that, it included features to run several parallel snapshots of the guest in near real-time. Those snapshots were carefully controlled to try and find or avoid multithreaded program bugs. It was an amazing technological achievement, but failed product. I learned from that experience that while people say they care about software quality, no one from developers to managers to end users is willing to pay for it. The world also changed under our feet. The AppStore happened. We live in the age of the $2 app. No one really expects it to work. |
Joseph Devietti, Brandon Lucia, Luis Ceze and Mark Oskin, DMP: Deterministic Shared Memory Multiprocessing, Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2009; IEEE Micro Top Picks 2009 Much more about DMP here |
Cheap manufacturing of large VLSI chips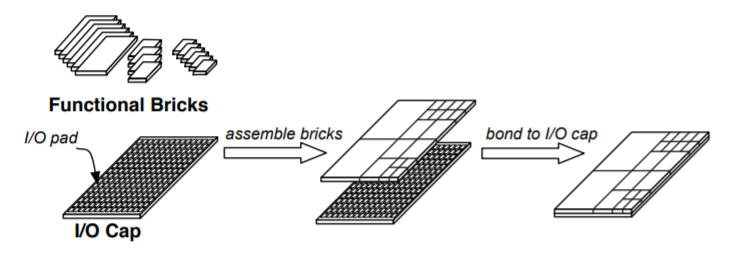 This project started out with a simple question that Todd Austin asked me one day as we walked across Red Square at UW, ``how do we make chip manufacturing so cheap you can do it at home?'' I thought about it for awhile and realized the key was the old 74xx series of TTL DIP parts. If we could make the modern day equivalent that then people could assemble the final bit at home. There would be components -- CPUs, PCIe controllers, accelerators, etc that people would order from the likes of digikey. They would also order a backplane chip, with an on-chip network used to interconnect anything. These would be bonded together ``at home'' and viola!
This project started out with a simple question that Todd Austin asked me one day as we walked across Red Square at UW, ``how do we make chip manufacturing so cheap you can do it at home?'' I thought about it for awhile and realized the key was the old 74xx series of TTL DIP parts. If we could make the modern day equivalent that then people could assemble the final bit at home. There would be components -- CPUs, PCIe controllers, accelerators, etc that people would order from the likes of digikey. They would also order a backplane chip, with an on-chip network used to interconnect anything. These would be bonded together ``at home'' and viola!
Now if that idea wasn't crazy enough for 2006/7 the project threw in something else too: those ``bricks'' would have precise shape to them and support automated self-assembly. That part of the vision never came to pass, but the idea of assembling chips from ``bricks'' did. We call them ``chiplets'' today and large commercial parts are assembled with both passive and active interposers. |
Martha Mercaldi, Mojtaba Mehrara, Mark Oskin and Todd Austin, Architectural Implications of Brick and Mortar Silicon Manufacturing, International Symposium on Computer Architecture (ISCA) 2007 Martha Mercaldi-Kim, John D. Davis, Mark Oskin and Todd Austin, Polymorphic On-Chip NetworksInternational Symposium on Computer Architecture (ISCA) 2008. Useful slides: here |
Quantum architectures
I started work on architectural support for quantum computers as a graduate student working with Fred Chong. Fred was good friends with Isaac Chuang who had just finished building a bulk-spin quantum computer at IBM and taken a job at MIT. After graduating I continued the work as an Assistant Professor at UW. The architecture community at the time had a wide range of opinions about quantum computing, from calling it ``mediocre science fiction, at best'' (a real review I received) to game-changing. We took the science fuction review with good cheer -- it became the motto for our research group. Somewhere I even still have our team T-shirt with it printed on it. Things have come a long way since then. We now have commercially available quantum computers and ``quantum supremacy'' has been achieved. Quantum architecture is now an accepted subdiscipline within computer architecture. I still work in a space adjacent to quantum computing, but not at UW. |
Mark Oskin, Frederic T. Chong, and Isaac Chuang. A Practical Architecture for Reliable Quantum ComputersIEEE Computer, Jan. 2002 Mark Oskin, Frederic T. Chong, Isaac Chuang and John Kubiatowicz. Building Quantum Wires: The Long and the Short of itInternational Symposium on Computer Architecture (ISCA), June 2003 Steven Balensiefer, Lucas Kregor-Stickles, Mark Oskin. An Evaluation Framework and Instruction Set Architecture for Ion-Trap based Quantum Micro-architectures, International Symposium on Computer Architecture (ISCA) 2005 Lucas Kreger-Stickles and Mark Oskin, Microcoded Architectures for Ion-Trap Quantum Computers, International Symposium on Computer Architecture (ISCA) 2008. |
WaveScalar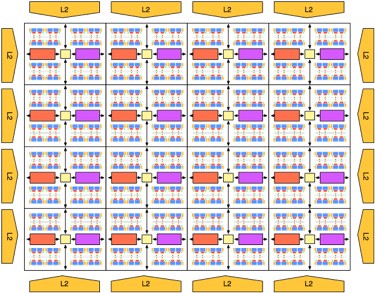
WaveScalar began as an effort to chase all the instruction level parallelism (ILP) one could ever have. We were inspired by pioneering work by Monica Lam with her paper on the limits of control flow on ILP. We focused on unlocking parallelism in imperative language programs (e.g. C) by unlocking the limits of control flow. Along the way, we realized we were really building a dataflow machine but not like one ever build before. This dataflow machine would have a conventional memory system and it would have hardware support to make dataflow execution of imperative software fast and correct. The project itself was extremely exciting to do, but in the end I learned something about ILP that has stuck with me to this day: there are two points of sequentialization in a superscalar processor, instruction fetch and memory reads/writes. WaveScalar parallelized instruction fetch to the absolute limit, but the memory interface was only parallelized to the limit of what a compiler could express to the hardware statically. This ultimately constrained performance. The challenge is still out there for another day: unlock the parallelism at the memory side. |
Steve Swanson, Ken Michelson, Andrew Schwerin and Mark Oskin. WaveScalar, 36th Annual International Symposium on Microarchitecture (MICRO-36), December 2003 Steve Swanson, Andrew Putnam, Martha Mercaldi, Ken Michelson, Andrew Petersen, Andrew Schwerin, Mark Oskin, and Susan Eggers, Area-Performance Trade-offs in Tiled Dataflow Architectures, International Symposium on Computer Architecture (ISCA) 2006. Martha Mercaldi, Steve Swanson, Andrew Petersen, Andrew Putnam, Andrew Schwerin, Mark Oskin and Susan Eggers, Instruction Scheduling for Tiled Dataflow Architectures, Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2006 Andrew Petersen, Martha Mercaldi, Steve Swanson, Andrew Putnam, Andrew Schwerin, Mark Oskin and Susan Eggers, Reducing Control Overhead in Dataflow Architectures, Symposium on Parallel Architectures and Compilation Techniques (PACT) 2006 Steven Swanson, Andrew Schwerin, Martha Mercaldi, Andrew Petersen, Andrew Putnam, Ken Michelson, Mark Oskin, Susan Eggers,The WaveScalar Architecture, Transactions on Computer Systems (TOCS) 2007 |